self-supervised pre-trained Document Image Transformer model, DiT를 제안 ⇒ 다양한 포맷의 문서와 대규모 unlabeled 문서 데이터에 대해서 학습되어야만 human-labeled document image에 의존적이지 X, 다양한 AI task를 잘 다룰 수 있다.
본 논문에서는 DiT를 Image classification, Document Layout Analysis, Table Detection, STD 등 다양한 Document AI task의 Backbone으로 활용하여 성능을 확인했고, 다양한 Task에 대해서 SoTA를 달성했다.
2. DiT
2.1 Model Architecture
ViT처럼 vanilla transformer를 Backbone으로 사용.
Document image를 겹치지 않는 여러개의 패치로 나눠서 시퀀셜한 형태의 patch embedding 생성, 1d positional embedding과 합쳐 각 image patch를 Transformer의 input으로 주고, multi-head attention을 적용하여 encoder로부터 각 이미지 패치에 대한 output을 받는다.
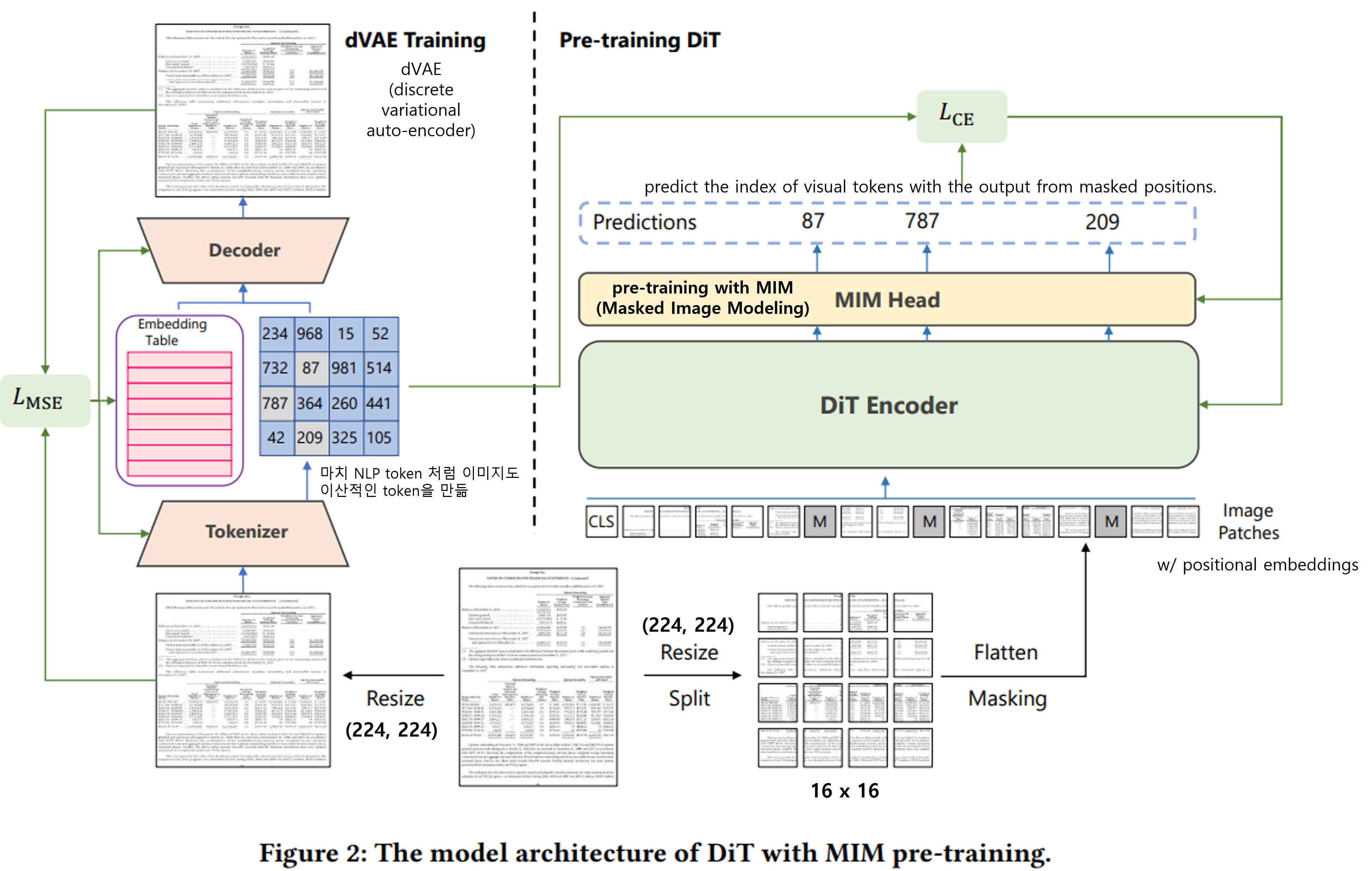
2.2 Pre-training
MIM(Masked Image Modeling) task
from BEiT idea
BEiT처럼 직접 dVAE를 IIT-CDIP 데이터셋(42 million document image set)으로 학습하여, image tokenizer로 활용.
랜덤하게 input 일부에 masking을 넣고(with special token[MASK]) 해당 영역에 맞는 visual token(from dVAE image tokenizer)을 예측하도록 학습
2.3 Fine-tuning
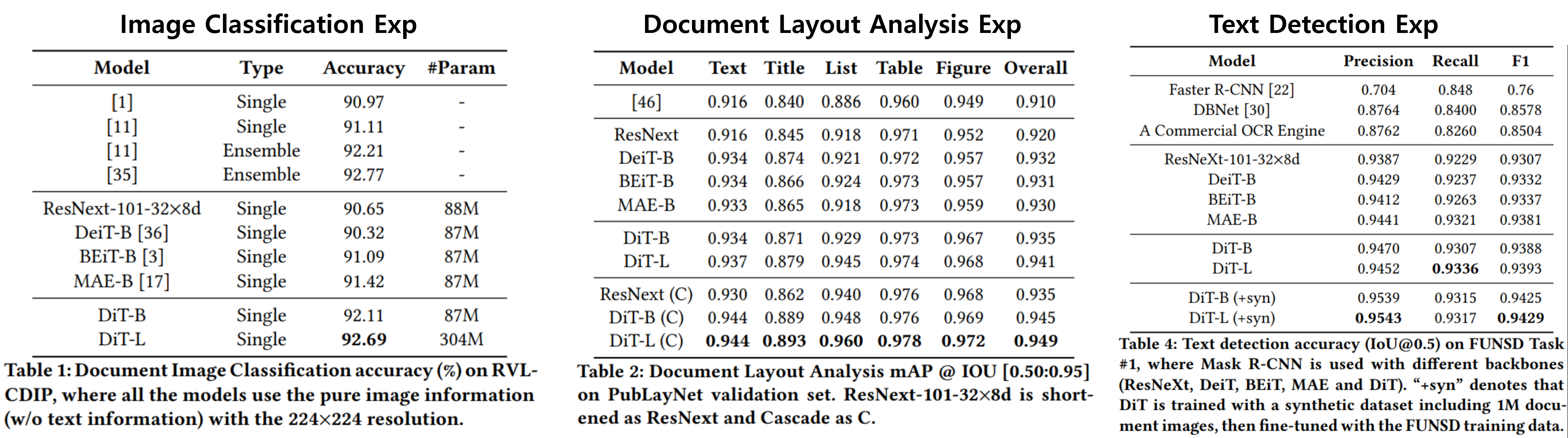
Document image classification : RVL-CDIP dataset
Document Layout Analysis : PubLayNet
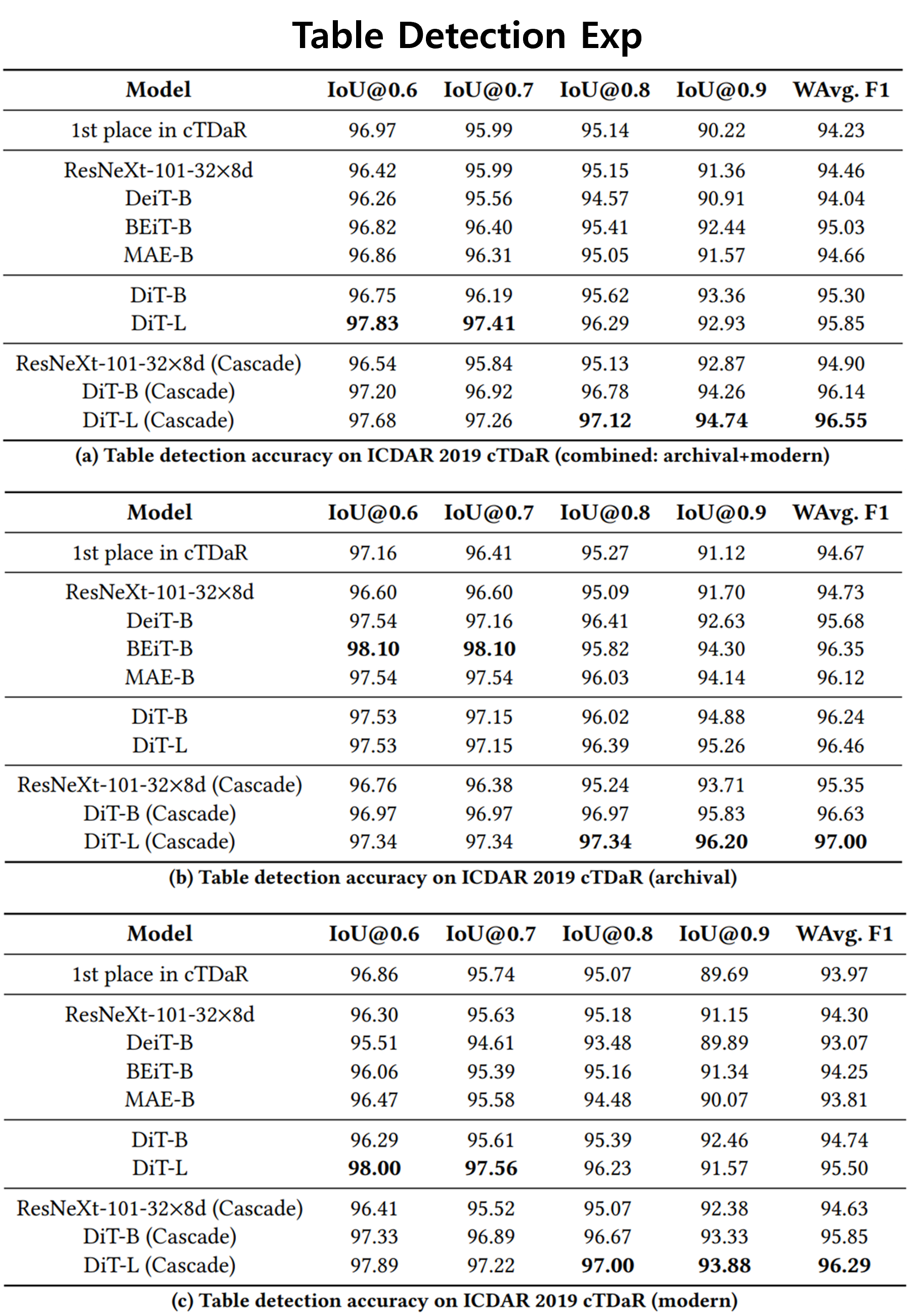
Table Detection : ICDAR 2019 cTDaR dataset
Text Detection : FUNSD dataset
⇒ 크게 Image Classification & Object Detection task로 분류할 수 있음.
Image Classification
Average Pooling을 사용해서 각 image patch를 종합하여 global representation을 만들고 해당 feature를 간단한 linear classifier 로 넘기도록 구성
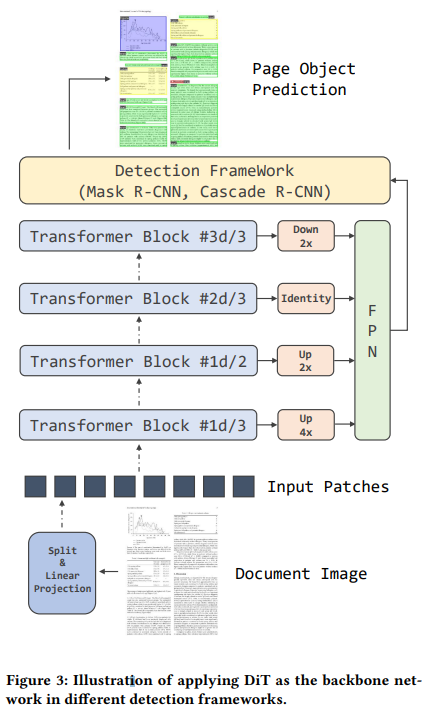
Object Detection
Mask R-CNN이랑 Cascade R-CNN을 Detection Framework로 쓰고, ViT 기반 모델을 backbone으로 사용.
서로 다른 4종류 해상도의 transformer block을 사용, single scale의 ViT를 multi-scal의 FPN이 적용될 수 있도록 구현함.
3. Experiments
3.1 Tasks(생략)
RVL-CDIP , PubLayNet, cTDaR, FUNSD dataset에 대한 간단 소개
3.2 Settings
선행학습 Setup
IIT-CDIP dataset으로 선행학습하여, document image에 대한 이미지 인코딩을 할 수 있도록 함.
multi page document는 각 페이지 단위로 분리해서 총 42M 문서 이미지를 토대로 학습