
※ 본 게시물에 사용된 내용의 출처는 대다수 <펭귄브로의 3분 딥러닝-파이토치맛>에서 사용된 자료이며, 개인적인 의견과 해석이 추가된 부분도 존재합니다. 그림의 경우 교재를 따라 그리거나, 제 임의대로 추가 수정한 부분도 존재합니다. 저 역시도 공부하고자 포스팅한 게시물이니, 잘못된 부분은 댓글로 알려주시면 감사하겠습니다.
- Aritificial neural network
- Node
- Input / hidden layer
- Activation function
- Backpropagation
- Vanishing Gradient
Artificial Neural Network(ANN) : 인공신경망
- 사람의 두뇌와 비슷한 방식으로 정보를 처리하기 위한 구조
- 입력층(Input layer)
: 입력 데이터를 받기 위한 layer, 사람으로 치면 자극을 입력받는 감각기관
- 은닉층(Hidden layer)
: 입력된 데이터를 해석하기 위한 layer, 주로 context 데이터를 생성하며 사람으로 치면 입력된 자극을 해석.
- 출력층(Output layer)
: 입력 데이터에 대한 출력 데이터를 도출

각 노드마다 수학연산을 실행하여 모델을 학습하며, 가장 핵심 변수는 아래와 같다.
가중치(weight), 편향(bias), 활성함수(activation function)
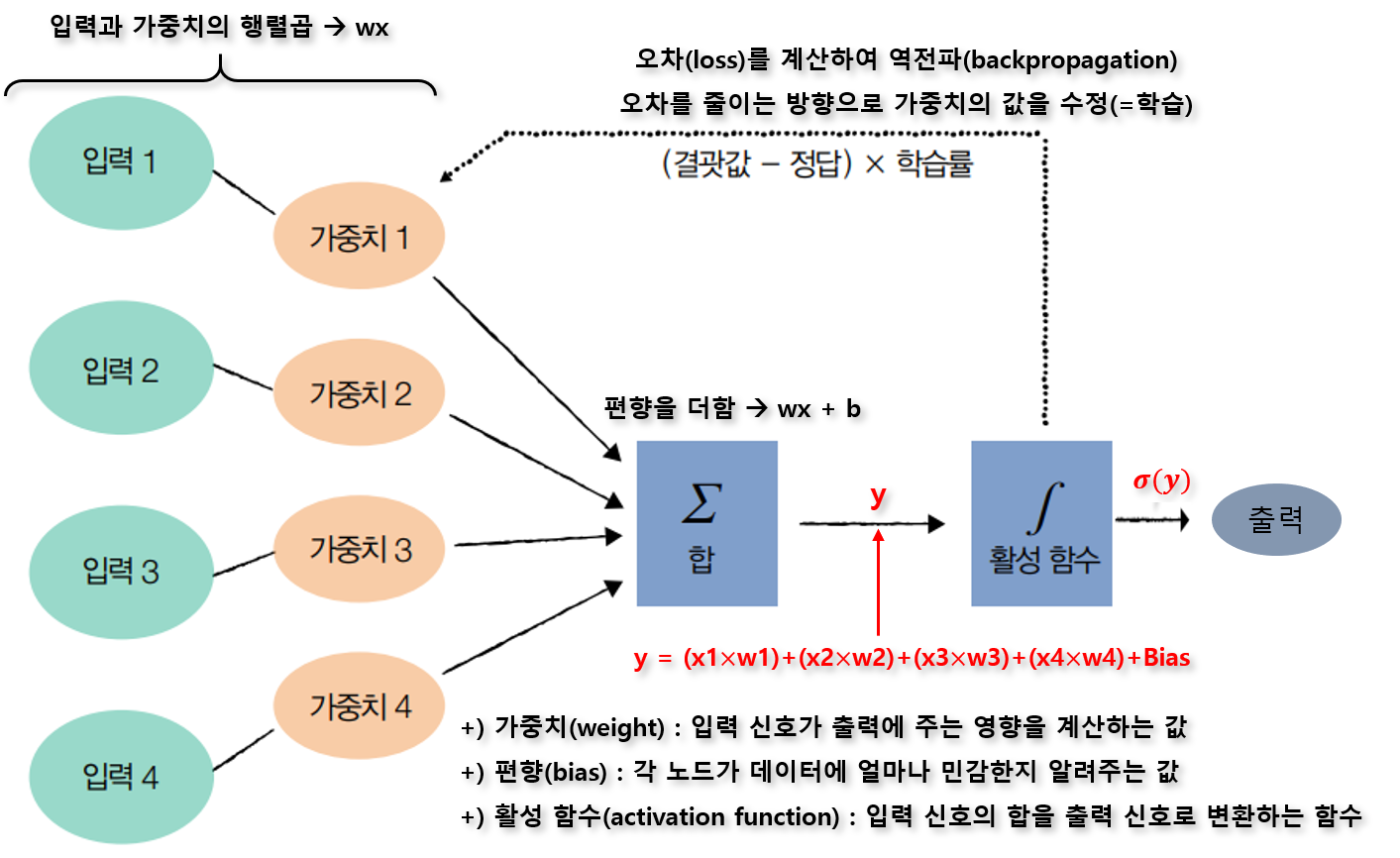
- 가중치(weight)
: 입력 신호가 출력에 주는 영향을 계산하는 매개변수
- 편향(bias)
: 각 노드가 데이터에 얼마나 민감한지 알려줄 수 있는 매개변수로 실제 사용자가 부여하거나 랜덤으로 초기화 하는 값
- 활성 함수(activation function)
: hidden layer내 계산된 결과값을 activation function을 거침으로써 activate 여부를 확인하고 실제 ANN의 결과값을 산출, 즉 현재 노드에서 계산된 값을 다음 뉴런으로 보내줄지 말지 결정하는 역할을 한다 봐도 좋다.
- 역전파(backpropagation)
: 내가 뽑고자 하는 target값과 실제 모델이 예측한 output(prediction)이 얼마나 차이 나는지 오차를 구한 후, 이전 Layer로 해당 오차를 전파해가며, 각 노드가 갖고 있는 변수를 갱신하는 알고리즘
Activation Function
- 대다수 비선형 함수를 사용하여 구현하며, 크게 아래 3개의 함수가 대표적이다. 이 외에도, Leaky ReLU, PReLU, ELU, Maxout 등 다양한 함수들이 존재하며, Task 종류에 따라 activation function의 종류도 큰 영향을 미친다.

- Sigmoid는 출력 값(y)를 0~1사이의 값으로 제한시키며, 데이터의 평균을 0.5로 수렴하도록 한다.
- 입력값이 크면 1, 작으면 0에 수렴하도록 동작한다.
- Logistic Regression(로지스틱 회귀)같은 분류(classification) 문제에 많이 사용되지만, 딥러닝 모델의 길이가 깊어질수록 gradient descent 과정에서 기울기값이 사라지는 "Vanishing Gradient"현상이 발생하며, 얉은 모델에만 사용됨.
- Vanishing Gradient(기울기 소실)
- : Loss를 통해서 앞부분 레이어의 Node를 업데이트 할 때, 아주 작은 기울기가 곱해지게 되면, 앞단의 레이어엔 기울기가 잘 전달되지 않고 소실되는 경우를 의미

- 대부분 sigmoid를 쓰면 성능이 낮기 때문에 비추천하지만, binary classification(이중 분류)문제에는 sigmoid를 사용.
- 출력 값(y)를 -1~1사이의 비선형 형태로 변경하기 위함.
- Sigmoid의 단점을 보완하기 위해 나와서, Sigmoid보다는 우수한 성능이지만 여전히 Vanishing Gradient 문제는 남아있음.
- Vanishing Gradient 문제를 해결하기 위한 함수로 x값이 음수일 경우 0을 출력하게끔 하는 함수.
- 다른 함수에 비해 경사 하강에 영향을 주지 않기 때문에 학습이 빠르다.
- 일반적으로 Hidden Layer에 사용되는 함수지만, 음수 값을 받는 경우 항상 0을 출력하기 떄문에 데이터 종류에 따라 훈련이 덜 될 수도 있다.
- 실제로 classification관련 Task에서 가장 많이 쓰이는 함수이며, 아래 수식과 같이 K개의 클래스에 대한 확률 분포, 즉 Logistic regression이라 볼 수 있다.
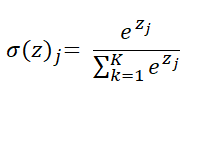
- DNN의 제일 마지막 Classification Layer(분류 , 최상단 레이어)에 사용되며 입력 데이터가 미리 정의된 클래스들에 대한 확률값으로 나타나게 된다.

이외의 다른 함수 및 더 자세한 설명은 아래 링크를 참고하면 좋다.
위키독스
온라인 책을 제작 공유하는 플랫폼 서비스
wikidocs.net