
※ 본 게시물에 사용된 내용의 출처는 대다수 <펭귄브로의 3분 딥러닝-파이토치맛>에서 사용된 자료이며, 개인적인 의견과 해석이 추가된 부분도 존재합니다. 그림의 경우 교재를 따라 그리거나, 제 임의대로 추가 수정한 부분도 존재합니다. 저 역시도 공부하고자 포스팅한 게시물이니, 잘못된 부분은 댓글로 알려주시면 감사하겠습니다.
- supervised learning
- classification
- regression
Supervised Learning(지도 학습)
Label이 존재하는 훈련 데이터로부터 특정 목적 함수를 유추할 수 있도록 반복된 학습을 진행하는 방법
크게 분류(classification)과 회귀(regression)으로 나뉠 수 있다.
- 분류(classification) : 데이터를 특정 클래스로 분류하는 작업을 의미하며, 클래스의 개수가 두개일 경우 이진 분류, 여러 개로 나뉠 경우 다중 분류로 세분화 될 수 있다.
ex) 이진 분류 : 참-거짓 구분/ 다중 분류 : 데이터 종류(실수형, 정수형, 문자형,...) 구분
- 회귀(regression) : 연속적인 데이터에 대해 특징을 잡아 실수형 값을 예측하는 형태.
ex) 집 값 예측하기

간단한 분류 모델 구현(예제)
sklearn 라이브러리의 make_blobs를 사용한 2차원 벡터 기반의 데이터셋으로 간단한 분류 모델 구현하기
yellowjs0304/3-min-pytorch_study
3분 딥러닝 파이토치맛 - 오픈소스 개인 스터디용. Contribute to yellowjs0304/3-min-pytorch_study development by creating an account on GitHub.
github.com
코드 실행에 필요한 라이브러리들을 임포트해준다.
- Numpy : 수치해석용 라이브러리로 가장 유명한 라이브러리, 대다수 행렬, 벡터 연산과정에 사용되며 머신러닝, 데이터 마이닝 과정에 널리 사용됨. Pytorch의 기본이라 할 수 있음.
- Scikit-learn : 파이썬의 대표적인 머신러닝 라이브러리
- Matplotlib : 주로 데이터 시각화를 위해 사용되며, 파이썬에서 Matlab과 유사하게 그래프 표시를 가능케 해줌.
import torch
import numpy
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 학습 데이터 생성을 위해 sklearn, numpy를 import해준다.
# matplotlib는 학습 데이터의 분포, 패턴 시각화를 위한 라이브러리
학습 과정에 사용되는 데이터는 scikit-learn의 make_blobs 함수를 통해 레이블을 생성하며, 랜덤한 점들을 생성하여 각 점들이 특정 클러스터(여기서는 총 4개: "0, 1, 2, 3")에 맵핑될 수 있도록 만든다.
# 2차원 벡터
n_dim = 2
# 학습을 위한 데이터셋 (80개)
x_train, y_train = make_blobs(n_samples=80, n_features=n_dim, centers=[[1,1],[-1,-1],[1,-1],[-1,1]], shuffle=True, cluster_std=0.3)
# 평가를 위한 데이터셋 (20개)
x_test, y_test = make_blobs(n_samples=20, n_features=n_dim, centers=[[1,1],[-1,-1],[1,-1],[-1,1]], shuffle=True, cluster_std=0.3)x_train를 출력해보면 아래와 같은 80개의 랜덤 2차 행렬들이 생성됨
[[-1.31848257 -1.04901165]
[-0.79974633 -1.21055172]
[-0.87837357 -1.24151137]
[ 1.5656206 0.9686919 ]
[-1.20842198 1.20543938]
...
[-1.02694298 1.19547134]
[-1.24018411 -1.07125376]
[-1.56414737 0.48678368]]
y_train은 아래와 같이 각 2차 행렬의 라벨이 나열된 것을 확인할 수 있다.
[2 2 3 2 1 2 2 0 0 2 2 0 0 3 0 1 0 1 0 0 0 1 0 3 1 1 0 0 3 3 1 3 2 0 3 2 3
1 1 2 2 1 1 3 1 1 3 3 0 2 0 3 3 3 2 0 0 1 2 0 3 1 1 0 2 0 2 3 3 3 1 1 2 3
3 2 2 2 1 1]간단한 분류 함수 구현을 위해, 상단에 구현한 4개의 라벨을 2개의 라벨로 합쳐서 0, 1로만 구분할 수 있도록 해보자.
==> 즉, 0 or 1일 경우엔 0 / 2 or 3일 경우엔 1로 맵핑
def label_map(y_, from_, to_):
y = numpy.copy(y_)
for f in from_:
y[y_ == f] = to_
return y
y_train = label_map(y_train, [0, 1], 0)
y_train = label_map(y_train, [2, 3], 1)
y_test = label_map(y_test, [0, 1], 0)
y_test = label_map(y_test, [2, 3], 1)label_map함수를 거친 후엔 아래와 같이 각 라벨이 0 또는 1로 변경된 것을 확인할 수 있다.
[1 1 1 1 0 1 1 0 0 1 1 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 1 0 1 1 0 1 1 1
0 0 1 1 0 0 1 0 0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 1 0 0 0 1 0 1 1 1 1 0 0 1 1
1 1 1 1 0 0]+) 참고로 랜덤함수라서 데이터는 각기 다 다를 수 있다.
학습 데이터의 분포를 시각화 하기 위한 함수
# 시각화 (0인 데이터는 점, 1인 데이터는 십자가)
def vis_data(x,y = None, c = 'r'):
if y is None:
y = [None] * len(x)
for x_, y_ in zip(x,y):
if y_ is None:
plt.plot(x_[0], x_[1], '*',markerfacecolor='none', markeredgecolor=c)
else:
plt.plot(x_[0], x_[1], c+'o' if y_ == 0 else c+'+')
plt.figure()
vis_data(x_train, y_train, c='r')
plt.show()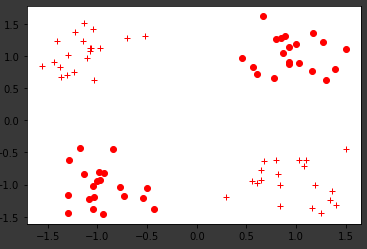
# 학습, 평가용 데이터를 Ndarray에서 Tensor형태로 변경해준다
x_train = torch.FloatTensor(x_train)
print(x_train.shape)
x_test = torch.FloatTensor(x_test)
y_train = torch.FloatTensor(y_train)
y_test = torch.FloatTensor(y_test)간단한 분류 네트워크를 정의한다.
class NeuralNet(torch.nn.Module): # 일반적으로 신경망 모듈을 상속받는 파이썬 클래스로 정의
def __init__(self, input_size, hidden_size): # 객체 생성시 자동 호출되는 init함수
super(NeuralNet, self).__init__() # NeuralNet 클래스가 nn.Module의 속성을 갖고 초기화된다.
self.input_size = input_size # 입력 데이터의 차원
self.hidden_size = hidden_size # Linear layer 내 은닉 유닛 개수
self.linear_1 = torch.nn.Linear(self.input_size, self.hidden_size) # torch.nn.Linear는 bias와 행렬곱을 포함한 연산을 지원할 수 있는 Linear layer를 반환한다.
self.relu = torch.nn.ReLU() # activation function ReLU 선언
self.linear_2 = torch.nn.Linear(self.hidden_size, 1)
self.sigmoid = torch.nn.Sigmoid() # acitivation function Sigmoid 선언
def forward(self, input_tensor):# 네트워크를 거칠 때 사용되는 함수
# linear 1 : [input_size, hidden_size] 크기의 가중치(weight)를 행렬곱 하고, bias를 더해 [1, hidden_size 꼴의 텐서를 반환한다]
linear1 = self.linear_1(input_tensor)
# relu함수를 적용 --> 입력 값이 0보다 작으면 0 / 0 이상이면 그대로 출력
relu = self.relu(linear1)
# Relu를 거친 텐서는 linear_2를 거치면서 [1, 1]사이즈로 변환되고,
linear2 = self.linear_2(relu)
# sigmoid함수를 거쳐서 0~1사이의 값을 반환
# ==> 최종적으로 이 데이터가 0 or 1 중 어느쪽에 더 가까운지 판별할 수 있음
output = self.sigmoid(linear2)
return output
학습에 필수적인 변수, 알고리즘 정의
#Input size를 2/ hidden_size를 5로 설정한 네트워크 객체 선언
model = NeuralNet(2, 5)
learning_rate = 0.03
# Binary Cross Entropy Loss 함수를 Loss function으로 적용
criterion = torch.nn.BCELoss()
# 전체 학습 데이터를 총 몇번 모델에 입력할지(몇 번 반복학습할지)
epochs = 2000
# Optimizer로 SGD(Stochastic Gradient Descent) 설정
# step()함수를 부를 때마다 가중치를 학습률만큼 갱신하므로,
# model.parameter()함수로 추출한 모델 내의 weight, learning rate을 입력
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)SGD : 확률적 경사하강법을 의미하며, 이전 이미지 복원과정과 동일하게 new_weight = weight - learning rate x gradient의 형태로 갱신된다.
아무런 학습도 하지 않은 모델의 성능을 테스트 하기 위해 model.eval함수 수행,
# 아무런 학습을 진행하지 않았을 때의 성능 테스트
model.eval()
# x_test(모델의 결과값)와 y_test(실제 레이블 값) 간의 차원을 동일하게 하기 위해서 squeeze()함수 사용
test_loss_before = criterion(model(x_test).squeeze(), y_test)
# Tensor 형태의 test_loss_before값을 스칼라 형태로 출력하기 위해 .item()함수 호출
print('Before Training, test loss is {}'.format(test_loss_before.item()))
아래 함수를 통해 본격적인 학습용 함수 구현
for epoch in range(epochs):# Epoch만큼 도는 함수
# Train 함수 호출(네트워크의 모드 전환 단계)
model.train()
# Epoch마다 새로운 gradient 계산을 위해 gradient를 0으로 설정
optimizer.zero_grad()
# 실제 학습 데이터를 입력하여, 결과값을 게산
# 이 때 수행되는 함수는 앞의 NeuralNet 클래스 내에서 정의한 forward함수
# nn.Module 이 알아서 forward를 호출해줌
train_output = model(x_train)
# x_test(모델의 결과값)와 y_test(실제 레이블 값) 간의 차원을 동일하게 하기 위해서 squeeze()함수 사용
train_loss = criterion(train_output.squeeze(), y_train)
# 100 Epoch마다 학습이 잘 되가는지 체크하기 위한 함수
if epoch % 100 == 0:
print('Train loss at {} is {}'.format(epoch, train_loss.item()))
# 오차함수를 gradient로 미분해서 오차가 최소가 되는 방향을 구하고
train_loss.backward()
# 그 방향으로 모델을 학습률만큼 이동 ==> backpropagation 수행하는 과정
optimizer.step()
실제로 학습해보고 테스트하면 아래와 같이 현저히 줄어든 것을 확인할 수 있다.
# 학습 후의 테스트
model.eval()
test_loss = criterion(torch.squeeze(model(x_test)), y_test)
print('After Training, test loss is {}'.format(test_loss.item()))
학습된 모델은 다음과 같이 state_dict()함수 형태로 바꾼 후, .pt파일로 저장하여 후에 다시 사용할 수 있다.
torch.save(model.state_dict(), './model.pt')
print('state_dict format of the model: {}'.format(model.state_dict()))+) state_dict() : 모델 내 가중치를 dictionary형태로 {연산 이름: weight tensor, bias tensor}저장한 데이터.
앞서 학습한 모델을 언제든지 이 파일(model.pt)을 다시 로딩해서 새로운 모델에 적용할 수 있다.
new_model = NeuralNet(2, 5)
new_model.load_state_dict(torch.load('./model.pt'))
new_model.eval()
print('벡터 [-1, 1]이 레이블 1을 가질 확률은 {}'.format(new_model(torch.FloatTensor([-1,1])).item()))