
※ 본 게시물에 사용된 내용의 출처는 대다수 <펭귄브로의 3분 딥러닝-파이토치맛>에서 사용된 자료이며, 개인적인 의견과 해석이 추가된 부분도 존재합니다. 그림의 경우 교재를 따라 그리거나, 제 임의대로 추가 수정한 부분도 존재합니다. 저 역시도 공부하고자 포스팅한 게시물이니, 잘못된 부분은 댓글로 알려주시면 감사하겠습니다.
- Overfitting
- Dropout
과적합, 드롭아웃
- Overfitting(과적합) : 머신러닝 모델이 학습 데이터에만 치중되어, 정작 테스트 데이터에서는 성능이 하락하는 경우
- Underfitting(과소적합) : 학습데이터도 제대로 학습하지 못한 경우
- Generalization(일반화) : 학습데이터와 학습되지 않은 실제 데이터 상에서 동시에 높은 성능을 내는 상태

실제 머신러닝에서의 가장 큰 관건은 과적합 방지로, 학습을 무한정 진행하면 결국 validation/test 데이터셋에 대해서는 성능이 떨어지는 것을 확인할 수 있다. 이를 방지하기 위해 매 순간 validation 셋을 사용하여 과적합 여부를 확인하고, validation set에 대해 성능이 나빠지기 직전에 조기 종료(early stopping)하여, 저장하면 해당 모델이 실생활에 가장 적합한 모델이라 할 수 있다.

Overfitting문제는 주로 모델이 깊어 파라미터 수가 많고, 복잡도가 높은 모델, 또는 학습 데이터셋의 양이 부족할 경우에 흔하게 발생하는 문제로 실제 머신러닝 과정에는 Overfitting을 방지하는 다양한 방법이 발전해왔다.
1. 데이터 늘리기(data augmentation)
: 이미지 데이터의 경우, 일부 자르기, 돌리기, 노이즈 추가, 색상 변경, 대칭 이동 등
2. 드롭 아웃(dropout)
: 네트워크 모델의 학습 과정 중 신경망 일부를 의도적으로 제하는 방법.
예를 들어 50% 드롭아웃일 경우, 학습 단계마다 절반의 뉴런만 사용하고, 검증, 테스트 단계에선 모든 뉴런을 다 사용한다. 이는 학습에서 배제된 뉴런 외 다른 뉴런들에게 가중치를 분산시키고, 개별 뉴런이 특정 feature에 고정되는 현상을 방지하기 위함이다.
ex) 반에서 아이들의 성적 향상을 위해서 특정 잘하는 아이 일부만 위주로 학습을 진행하는 것이 아니라, 잘 모르는 틀리는 학생도 같이 참여시키면서 전체적인 반의 이해도를 올리도록 한다.

3. 모델의 복잡도 줄이기
: hidden layer의 개수 또는 매개변수의 수를 줄임으로써, 복잡도를 낮출 경우 과적합을 막을 수 있다.
4. 앙상블 모델(Ensemble)
: 모델을 여러 개를 만들어서 하나의 데이터를 각 모델에 넣어 N개의 결과값 중 여러 번 나온 결과를 택하는 경우.
5. Batch Normalization(배치 정규화)
: 간단히 말하자면 activation function의 실제 활성화 값 or 출력값을 정규화(정규분포화) 하는 것을 의미한다. 먼저 정규화의 의미부터 정리하자면, 정규화는 아래 그림처럼 복잡한 네트워크를 완화하여 학습을 더 빨리하거나 local optimum(특정 구간에 빠져버려 더 이상 학습이 진척되지 않는 상태)문제가 덜 발생하기 위함이다.
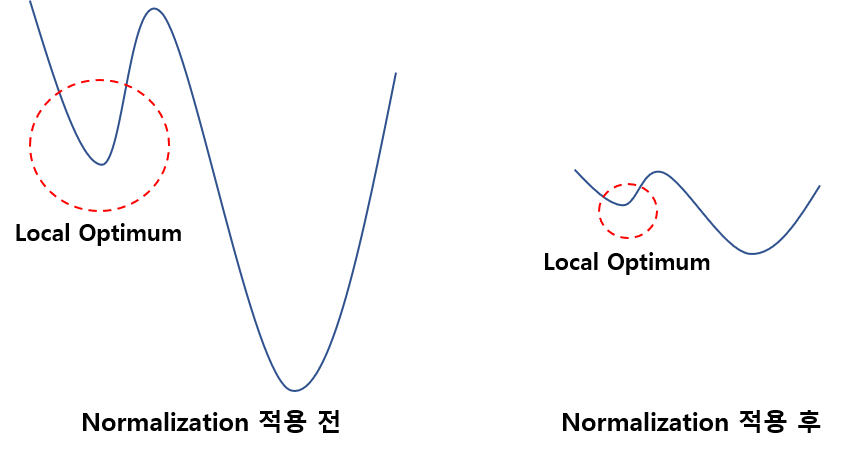
이때 Batch Normalization을 주장했던 논문에서 가장 큰 문제점으로 꼽은 개념은 Internal Covariate Shift라는 개념으로, DNN의 깊이가 깊어짐에 따라 각 layer마다 학습 과정에서 내부 파라미터가 변경되게 되고, 이는 결국 각 레이어마다 학습 데이터의 분포가 초기에 설정한 과정과 점점 다르게 변경될 수 있다는 것을 의미한다. 아래 그림을 참고하면 더 간단하게 이해할 수 있을 것이다.

결국, Batch Normalization의 핵심은 이런식으로 레이어마다 변화되는 데이터 분포를 다시 올바르게 Normalization(정규화)하는 추가 레이어를 둠으로써, 앞에서 말한 잘못되는 문제를 해결할 수 있도록 하는 것을 의미한다. 이때 각 batch 마다 normalization을 수행하는 것이 batch normalization이다. 자세한 과정은 논문의 알고리즘을 참고하면 수학적으로 분석할 수 있다.
본 책에는 다뤄지지 않았지만, 개인적으로 사실 Batch Normalization과 이미지 데이터 증가 기법이 효과가 좋다고 생각한다. pytorch에서 Batch Normalization을 사용하는 방법은 다음 튜토리얼을 따라 진행하면 된다.
앞에서 말한 5가지의 대표 기법 외에도 다양한 방법이 존재하며, 본 책에서는 이미지 변형(즉, 데이터 증가), Dropout 예제를 다루고 있으므로, 아래 코드로 실제로 수행해보도록 하자.
데이터 늘려보기
- 사용 코드
yellowjs0304/3-min-pytorch_study
3분 딥러닝 파이토치맛 - 오픈소스 개인 스터디용. Contribute to yellowjs0304/3-min-pytorch_study development by creating an account on GitHub.
github.com
본 예제에서는 이미지의 오른쪽과 왼쪽을 뒤집는 가로 대칭 이동 전략을 사용해보도록 한다.
torchvision의 transforms package를 사용하면 아래 코드처럼 Dataloader에 직접 torchvision data셋을 넣어주고 간결하게 재구성할 수 있다.
# Train Data Loader
train_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST('./.data',
train=True,
download=True,
transform=transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
# Test Data Loader
test_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST('./.data',
train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)이때의 관건은 transforms.Compose함수를 호출하고, 같이 사용한 RandomHorizontalFlip함수이며, 이 함수는 이미지를 무작위로 수평 뒤집기 하여 학습 예제를 2배 늘릴 수 있다.
랜덤 뒤집기이므로, 실제로 수행해보면 아래와 완전 동일하지 않고 이 중에서 일부만 뒤집혀져 있을 것이다.

이번 예제에서는 여기서 그치지 않고 앞서 말한 Dropout함수까지 함께 적용하여 테스트를 진행한다.
class Net(nn.Module):
def __init__(self, dropout_p=0.2):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 10)
# 드롭아웃 확률
self.dropout_p = dropout_p
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.fc1(x))
# 드롭아웃 추가
x = F.dropout(x, training=self.training,
p=self.dropout_p)
x = F.relu(self.fc2(x))
# 드롭아웃 추가
x = F.dropout(x, training=self.training,
p=self.dropout_p)
x = self.fc3(x)
return x그 전과 비슷하지만, fully connected layer 3개 외에 Dropout도 추가한 것을 볼 수 있다. 여기서는 0.2로 설정해놓았으며, 이는 학습과정 중 20%의 뉴런은 사용하지 않는다는 것을 의미한다.
자세한 네트워크 설명 및 이 이후의 코드는 앞선 포스팅에서 다루었으므로, 여기서는 자세히 작성하지 않겠다.
model = Net(dropout_p=0.2).to(DEVICE)
optimizer = optim.SGD(model.parameters(), lr=0.01)
끝까지 다 돌리면 초기 설정대로 약 50 Epoch를 돌지만 17만 돌았을때에도 아래처럼 꽤 좋은 성능을 보이고 있다.
