
※ 본 게시물에 사용된 내용의 출처는 대다수 <펭귄브로의 3분 딥러닝-파이토치맛>에서 사용된 자료이며, 개인적인 의견과 해석이 추가된 부분도 존재합니다. 그림의 경우 교재를 따라 그리거나, 제 임의대로 추가 수정한 부분도 존재합니다. 저 역시도 공부하고자 포스팅한 게시물이니, 잘못된 부분은 댓글로 알려주시면 감사하겠습니다.
- RNN(Recurrent Neural Network)
- 영화 리뷰 감정 분석
- Seq2Seq 기계 번역
RNN(Recurrent Neural Network)
이전까지 다룬 이미지는 정적인 데이터이다. 이미지를 구성하는 가로, 세로 행렬 내에 정해진 숫자가 나열되어 있는 형태로 이 데이터는 외부의 조작이 있지 않는 이상, 시간이 지나도 변하지 않는다.
- Sequential Data(시계열 데이터) : 데이터 집합 내 객체들이 어떤 순서를 갖는 데이터.
문서 데이터, 영상(video), 음성 신호, 주가 변동, 지진파, 센서 데이터, DNA 염기서열....실세계의 대다수 데이터가 포함됨
- RNN(Recurrent Neural Network) : 정해지지 않은 길이의 배열을 읽고 설명하는 신경망, Sequential Data 해석, 처리에 적합한 모델


상단 예제와 같이, RNN은 단순히 사과라는 사전적인 의미뿐만 아니라, 앞 뒤 문장의 단어들을 종합적으로 고려하여 의미를 파악하고 해석할 줄 안다. 이 외에도 오른쪽 그림과 같이 일련의 주식 데이터를 보고 추이를 예측할 수도 있다.
RNN의 동작 방식은 아래와 같다.
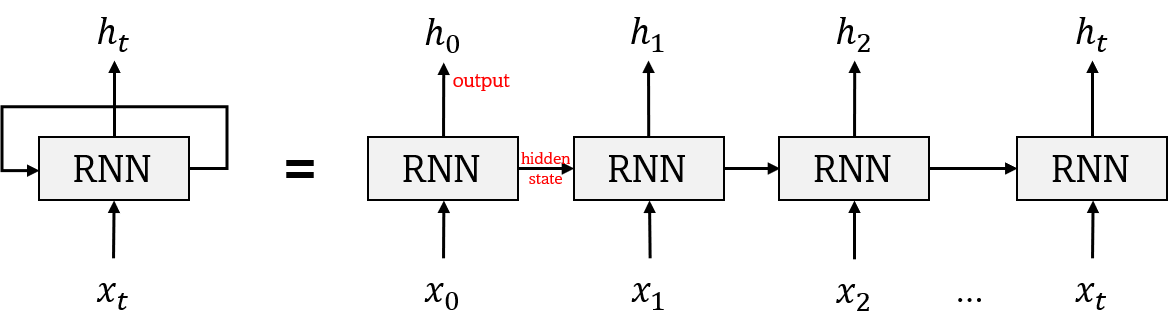
좌측 그림이 실제 외부에서 보는 RNN의 모습이며, 오른쪽이 동일한 과정을 시간에 따라 펼쳐놓은 모습이다. RNN의 핵심은 오른쪽처럼 지금까지 입력받은 데이터 흐름을 모두 내포하며, 이는 정보를 입력받을 때마다 지금까지 입력된 벡터를 종합하여 은닉 벡터(hidden vector)를 만들어낸다는 것을 의미한다.
단순하지만, RNN은 t 시점에 들어온 입력 데이터 $x_{t}$를 받아 은닉 벡터 $h_{t}$를 만들게 된다. 이때, 생성된 은닉 벡터 $h_{t}$는 다음 t+1시점에 입력 데이터인 $x_{t+1}$과 함께 RNN의 입력으로 들어가게 되며, RNN은 이들을 모두 압축한 $h_{t+1}$을 만들게 된다. 이 과정이 반복되게 되면 마지막 은닉 벡터는 이전까지의 모든 벡터 내용을 압축한 벡터라 말할 수 있다.
RNN은 앞에서 말한 것처럼 대표적인 시계열 데이터인 텍스트, 자연어 처리 및 학습에 사용되며, 대표적으로 LSTM(long short term memory), GRU(gated recurrent unit) 등 다양한 응용 RNN이 개발되어 언어 모델링, 텍스트 감정 분석, 기계 번역 등에 활발히 사용되고 있다. 이 외에도 앞서 언급한 주가 데이터, 비디오 처리까지 다양한 분야에도 활용될 수 있다. 마지막으로 앞에서 본 형태 외에 입력, 출력의 형태에 따라 아래와 같은 다양한 형태의 RNN이 제작될 수 있다.
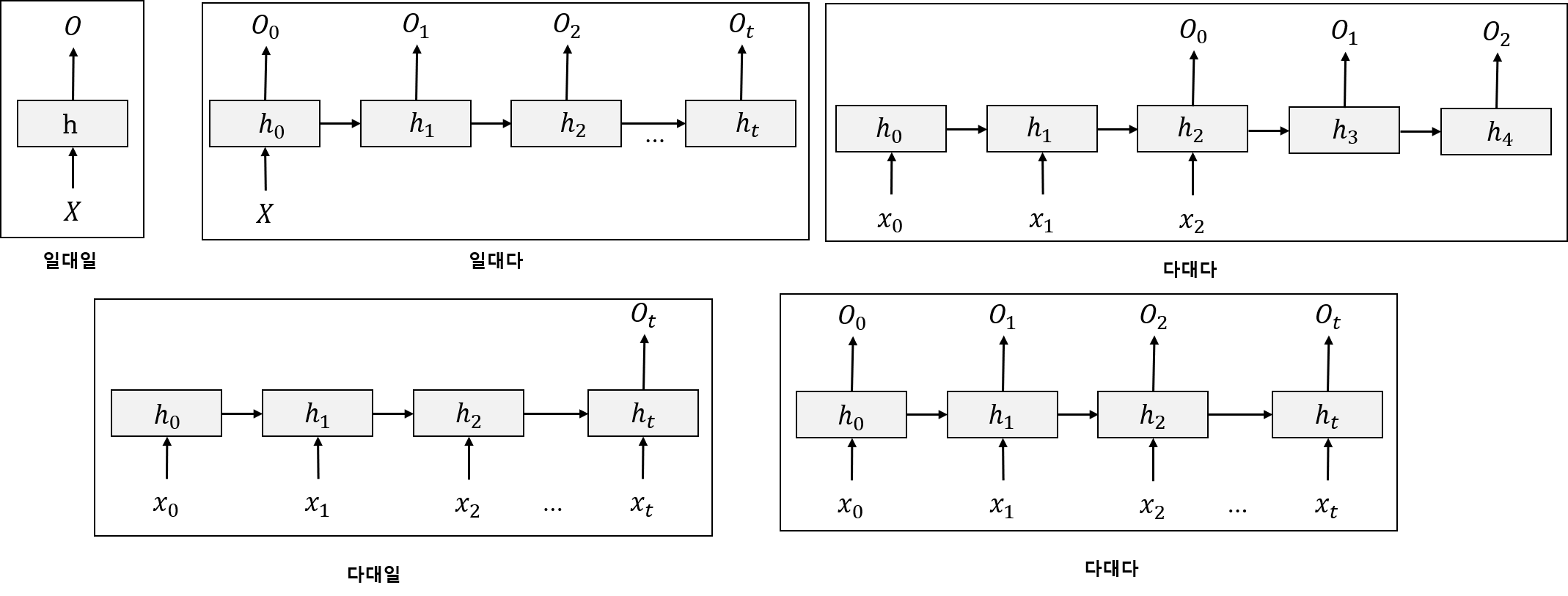
각 형태에 따른 대표적인 활용 예제는 아래와 같다.
- 일대일 : 일반적인 신경망
- 일대다 : 캡셔닝(이미지 보고 이미지 내 상황을 글로 표현)
- 다대일 : 문장 감정 분석(순차적 데이터를 보고 값 하나를 출력)
- 다대다(우상단) : 챗봇, 기계 번역
- 다대다(우하단) : 비디오 분류(매 프레임 레이블링)
영화 리뷰 감정 분석
- IMDb
www.imdb.com
- 영화 리뷰 5만건
- 대다수 영어 문장
- 긍정적 영화 리뷰는 2, 부정적 영화 리뷰는 1로 라벨링(Labeling)됨
이번에는 영화 리뷰 데이터셋(IMDb) 내 문장을 보고, 해당 문장의 감정을 분석하는 Task를 학습하고자 한다. 아래 그림처럼 영화 리뷰 텍스트를 RNN에 입력하고 영화평 전체 내용을 판단하여 해당 리뷰가 긍정적인지, 부정적인지를 판단해주는 간단한 분류 모델을 만들어보자.
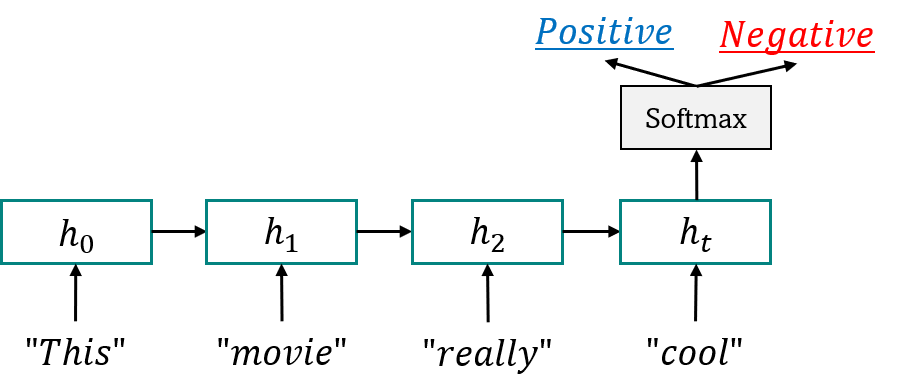
- 사용 코드
yellowjs0304/3-min-pytorch_study
3분 딥러닝 파이토치맛 - 오픈소스 개인 스터디용. Contribute to yellowjs0304/3-min-pytorch_study development by creating an account on GitHub.
github.com
모델을 정의하기 전에 필요한 패키지를 임포트하고, 하이퍼 파라미터도 정의한다.
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchtext.legacy import data, datasets
#자연어 데이터 처리를 위해서 torchtext 임포트
# 기존 코드에는 TorchText 0.8.0으로 셋팅되어 있어서 from torchtext import data, datasets로 명시 되어 있는데
# 코랩에 깔려있는 TorchText의 경우, 0.9.0 버전이기에 from torchtext를 torchtext.legacy로 변경해주어야 한다.
# 하이퍼파라미터 정의
BATCH_SIZE = 64
lr = 0.001
EPOCHS = 10
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")#GPU, CPU
print("다음 기기로 학습합니다:", DEVICE)필요한 패키지를 임포트하고, 하이퍼 파라미터도 정의한다. 이번에는 이미지 데이터가 아닌, 자연어 데이터를 처리하기 위해서 torchtext 라이브러리를 임포트한다. torchtext 라이브러리 내에는 Pytorch에서 미리 정의해둔 NLP, Text와 관련된 기계학습, 딥러닝을 위한 전처리 코드가 정의되어 있으며 예를 들면 vocab 생성, word vector, tokenizer 등의 라이브러리가 정의되어 있다.
"AttributeError: module 'torchtext.data' has no attribute 'Field'"
(+) 얼마전에 torchtext 0.9.0 버전으로 업그레이드 되면서 몇몇의 torchtext.data 내 라이브러리가 torchtext.legacy.data 로 변경되었다. 따라서, 아마 기존 코드를 그대로 사용할 시, 아래와 같은 오류가 발생할 것이다.
이럴 경우엔 torchtext를 0.8.0으로 다운그레이드 해주거나 torchtext.legacy.data로 변경해주자.

[관련 안내 링크]
# 데이터 로딩하기
print("데이터 로딩중...")
# data.Field 설명 #
# sequential인자 : TEXT는 Sequential 데이터라 True, Lable은 비Sequential이라 False로 설정
# batch_first : Batch를 우선시 하여, Tensor 크기를 (BATCH_SIZE, 문장의 최대 길이)로 설정
# lower : 소문자 전환 인자
# # # # # # # # # #
TEXT = data.Field(sequential=True, batch_first=True, lower=True)
LABEL = data.Field(sequential=False, batch_first=True)
#IMDB 데이터 로딩
trainset, testset = datasets.IMDB.splits(TEXT, LABEL)
# data.Field.build_vocab() 라이브러리
# 문장 내 단어와 Integer index 를 매칭시키는 단어장(vocab)을 생성 == 워드 임베딩을 위한 Vocab 생성
# <UNK> = 0, <PAD> = 1 토큰도 추가.
# min_freq : 최소 5번 이상 등장한 단어들만 사전에 담겠다는 것.
# 5번 미만으로 등장하는 단어는 UNK라는 토큰으로 대체
TEXT.build_vocab(trainset, min_freq=5)# TEXT 데이터를 기반으로 Vocab 생성
LABEL.build_vocab(trainset)# LABEL 데이터를 기반으로 Vocab 생성데이터 로딩을 위해 torchtext.data.Field 함수를 이용하여 TEXT, LABEL 필드를 정의한다. 여기서의 필드는 텐서로 표현될 수 있는 텍스트 데이터 타입을 처리하는 용어로, 각 토큰을 숫자 Index로 맵핑해주는 Vocabluary 객체 정의, 토큰화 하는 함수, 전처리 등을 인자로 지정해 줄 수 있다.
# 학습용 데이터를 학습셋 80% 검증셋 20% 로 나누기
trainset, valset = trainset.split(split_ratio=0.8)
# 매 배치마다 비슷한 길이에 맞춰 줄 수 있도록 iterator 정의
train_iter, val_iter, test_iter = data.BucketIterator.splits(
(trainset, valset, testset), batch_size=BATCH_SIZE,
shuffle=True, repeat=False)
vocab_size = len(TEXT.vocab)
n_classes = 2
# Positive, Negative Class가 두 개실제로 train_iter안에 있는 데이터를 보고 싶어서 아래와 같은 문장을 추가해봤다.
# Test #
for batch in train_iter:
print(batch.text)
print(batch.label)
break 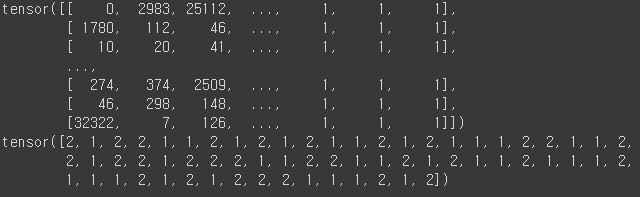
상단 이미지처럼 몇줄의 문장만으로 문장을 구성하는 단어를 Vocab에서 찾아, Integer형태로 변경한 모습을 볼 수 있다. 또한, 바로 아래는 라벨링된 리스트가 보인다.
print("[학습셋]: %d [검증셋]: %d [테스트셋]: %d [단어수]: %d [클래스] %d"
% (len(trainset),len(valset), len(testset), vocab_size, n_classes))
실제 로딩된 데이터 사양을 보면 다음과 같이 출력된다.
이제 본격적인 모델을 구성해보자
본 예제에서는 GRU라고 하는 RNN을 포함하는 신경망을 만들어 사용하도록 한다.
GRU에 대한 자세한 설명은 다음 포스팅에서 다루지만, 간단하게 설명하자면 RNN의 입력이 길어지면서 발생할 수 있는 정보 손실(gradient vanishing, gradient explosion) 문제를 sequential data 안의 벡터 간 정보 전달량을 조절함으로써 기울기를 조절하고 긴 문장 정보가 끝까지 전달될 수 있도록 도와준 모델 중 하나이다. 조금 더 자세한 내용은 다음 포스팅에서 이어서 진행하겠다.
class BasicGRU(nn.Module):
def __init__(self, n_layers, hidden_dim, n_vocab, embed_dim, n_classes, dropout_p=0.2):
super(BasicGRU, self).__init__()
print("Building Basic GRU model...")
self.n_layers = n_layers # 일반적으로는 2
#n_vocab : Vocab 안에 있는 단어의 개수, embed_dim : 임베딩 된 단어 텐서가 갖는 차원 값(dimension)
self.embed = nn.Embedding(n_vocab, embed_dim)
# hidden vector의 dimension과 dropout 정의
self.hidden_dim = hidden_dim
self.dropout = nn.Dropout(dropout_p)
#앞에서 정의한 하이퍼 파라미터를 넣어 GRU 정의
self.gru = nn.GRU(embed_dim, self.hidden_dim,
num_layers=self.n_layers,
batch_first=True)
#Input: GRU의 hidden vector(context), Output : Class probability vector
self.out = nn.Linear(self.hidden_dim, n_classes)다른 모델처럼 nn.Module을 상속받은 클래스를 정의한다. 네트워크 내부 구조를 정의한다. 이때, n_layers는 hidden vector들의 "층"(layer)로 복잡한 모델이 아닌 이상, 2로 설정하는 것이 일반적이다.
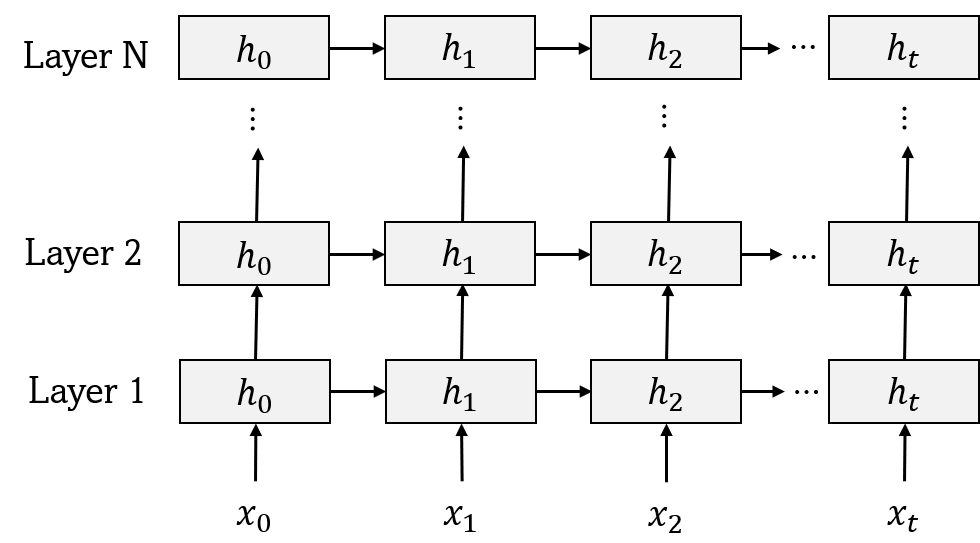
RNN의 내부에 필요한 embedding dimension(차원 값)과 hidden vector의 dimension(self.hidden_dim) 등을 같이 정의해주고 GRU network를 파라미터에 맞춰 정의해준다.
GRU는 앞서 언급했던 것처럼 연속된 데이터를 다 받아 최종적으로 전체 문장에 대한 context(맥락)정보를 담게 된다. 이 정보를 토대로 해당 리뷰가 긍정, 부정인지를 판별하기 위해서는 압축했던 tensor를 Linear layer에 통과하여 각 클래스에 대한 예측을 출력할 수 있도록 해준다.
이는 CNN 과정에서 마지막에 Linear layer를 통과시키면서 클래스를 분류 시키는 것과 동일한 과정이다.
지금까지는 init함수이고, 이제 본격적으로 forward함수를 구현해본다.
def forward(self, x):
# Input data: 한 batch 내 모든 영화 평가 데이터
x = self.embed(x)# 영화 평 임베딩
h_0 = self._init_state(batch_size=x.size(0)) # 초기 hidden state vector를 zero vector로 생성
x, _ = self.gru(x, h_0) # [i, b, h] 출력값 : (batch_size, 입력 x의 길이, hidden_dim)
# h_t : Batch 내 모든 sequential hidden state vector의 제일 마지막 토큰을 내포한 (batch_size, 1, hidden_dim)형태의 텐서 추출
# 다른 의미로 영화 리뷰 배열들을 압축한 hidden state vector
h_t = x[:,-1,:]
self.dropout(h_t)# dropout 설정 후,
# linear layer의 입력으로 주고, 각 클래스 별 결과 logit을 생성.
logit = self.out(h_t) # [b, h] -> [b, o]
return logit초반, Input data인 x는 하나의 Batch 내에 등장하는 모든 영화 평가 문장의 집합이며, 이는 설정한 batch size에 따라 크기가 다르다. 일반적으로 x의 크기는 (Batch_size, MAX_length)라 보면 된다. 이어서 입력 데이터를 임베딩 한 후, 네트워크의 초기 hidden vector(h_0)를 zero vector로 설정하는데, 이때 _init_state()라는 함수를 써서 Batch size를 입력받은 후, zero weight를 설정해 줄 수 있다.
+) 임베딩 : 여기서 사용하는 nn.Embedding은 일종의 룩업(lookup)테이블 형태로 단어별 고유의 vector를 저장할 수 있는 네트워크이다. 이 역시 사용자가 미리 정의하는 vocabulary 사이즈, embedding dimension에 따라 학습 과정에서 같이 학습되며, 단어의 의미가 비슷할수록 vector값도 비슷하다 생각하면 된다. 아래 사진을 보면 임베딩의 개념을 정확히 알 수 있을 것 같다.

train함수는 이전과 큰 차이점이 없이 loss를 cross_entropy를 사용해 모델의 예측값과 실제 label간의 차를 계산한다.
def train(model, optimizer, train_iter):
model.train()
for b, batch in enumerate(train_iter):
x, y = batch.text.to(DEVICE), batch.label.to(DEVICE)
y.data.sub_(1) # 레이블 값을 (기존 1, 2)에서 0과 1로 변환
optimizer.zero_grad()# 매번 기울기를 새로 계산하기 위해서 zero 로 초기화
logit = model(x)#모델의 예측값 logit 계산
loss = F.cross_entropy(logit, y)# logit과 실제 label간의 오차를 구하고 기울기 계산
loss.backward()
optimizer.step()+) Logit은 사실상 클래스 별 odds개념(인지 아닌지? 해당 사건이 일어날지, 일어나지 않을지?)에 log를 씌운 값으로 그냥 간단하게 특정 클래스일 확률을 [-무한대, +무한대]로 나타낸 것이다. 확률이 크면 logit도 커지므로, logit이 크다는건 해당 클래스에 대한 확률이 크다는 것도 같은 말인 것 같다. (간단하게 말하면 Logit이란 개념은 Negative일 확률 0.8, Positive일 확률 0.5 이런식으로 스코어링 한 것이고 각 클래스 별 값을 다 더한다고 1이 되진 않는다. 다 더했을 때 1이 되는 경우는 softmax를 적용했을 때의 얘기) 자세한 내용은 다음 유튜브 강의가 잘 나와 있으므로 참고하기 바란다.
평가 함수는 큰 차이가 없이 validation set에 대한 평균 오차, 평균 정확도를 계산할 수 있게 해준다.
def evaluate(model, val_iter):
"""evaluate model"""
model.eval()
corrects, total_loss = 0, 0
for batch in val_iter:# Validation 데이터셋에 대하여
x, y = batch.text.to(DEVICE), batch.label.to(DEVICE)
y.data.sub_(1) # 레이블 값을 0과 1로 변환
logit = model(x)
loss = F.cross_entropy(logit, y, reduction='sum')
total_loss += loss.item()
corrects += (logit.max(1)[1].view(y.size()).data == y.data).sum()
#전체 validation 셋에 대한 평균 loss와 accuracy를 구하는 과정
size = len(val_iter.dataset)
avg_loss = total_loss / size
avg_accuracy = 100.0 * corrects / size
return avg_loss, avg_accuracy
학습 시작 전, 모델 객체, optimizer를 정의한다. Adam을 optimizer로 사용하여 빠른 학습 속도를 주었다.
model = BasicGRU(1, 256, vocab_size, 128, n_classes, 0.5).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)학습을 진행하며, Epoch마다 validation loss와 accuracy를 찍어주도록 하였다.
best_val_loss = None
for e in range(1, EPOCHS+1):
train(model, optimizer, train_iter)
val_loss, val_accuracy = evaluate(model, val_iter)
print("[이폭: %d] 검증 오차:%5.2f | 검증 정확도:%5.2f" % (e, val_loss, val_accuracy))
# 검증 오차가 가장 적은 최적의 모델을 저장
if not best_val_loss or val_loss < best_val_loss:
if not os.path.isdir("snapshot"):
os.makedirs("snapshot")
torch.save(model.state_dict(), './snapshot/txtclassification.pt')
best_val_loss = val_loss
Validation loss가 가장 적은 모델을 최적 모델로 잡고 해당 모델을 저장해준다.
model.load_state_dict(torch.load('./snapshot/txtclassification.pt'))
test_loss, test_acc = evaluate(model, test_iter)
print('테스트 오차: %5.2f | 테스트 정확도: %5.2f' % (test_loss, test_acc))저장된 모델을 Test set에 대하여 측정해본다. 약 87퍼센트의 성능을 보여준다.

Seq2Seq 기계 번역
NLP 과정에서 꽃이라 할 수 있는 Machine translation 과정은 RNN기반의 번역 모델인 Seq2Seq(Sequence-to-Sequence)모델을 바탕으로 구현할 수 있다. 본 예제에서는 기존의 heavy한 기계 번역 모델을 간소화 하여 한 언어 문장을 다른 언어 문장으로 번역하지는 못하고, 영어 알파벳 문자열("hello")를 한글자씩 변경하여 스페인어 문자열("hola")로 번역하는 작은 모델로 다뤄보도록 한다.
- Seq2Seq(Sequence-to-Sequence)
: Encoder-Decoder 형태를 보유, 입출력 데이터 형태가 모두 sequential data.
Encoder와 Decoder의 역할은 앞선 포스팅에서 한번 다뤘지만 간단히 말하면 아래와 같으며, 간단한 번역 모델은 아래와 같다.
- Encoder
: 입력 데이터를 받아 문장의 뜻을 내포하는 고정 크기의 텐서(=문맥 벡터, context vector)를 생성.
- Decoder
: Encoder의 context vector값을 받아, 출력값을 차례로 예측
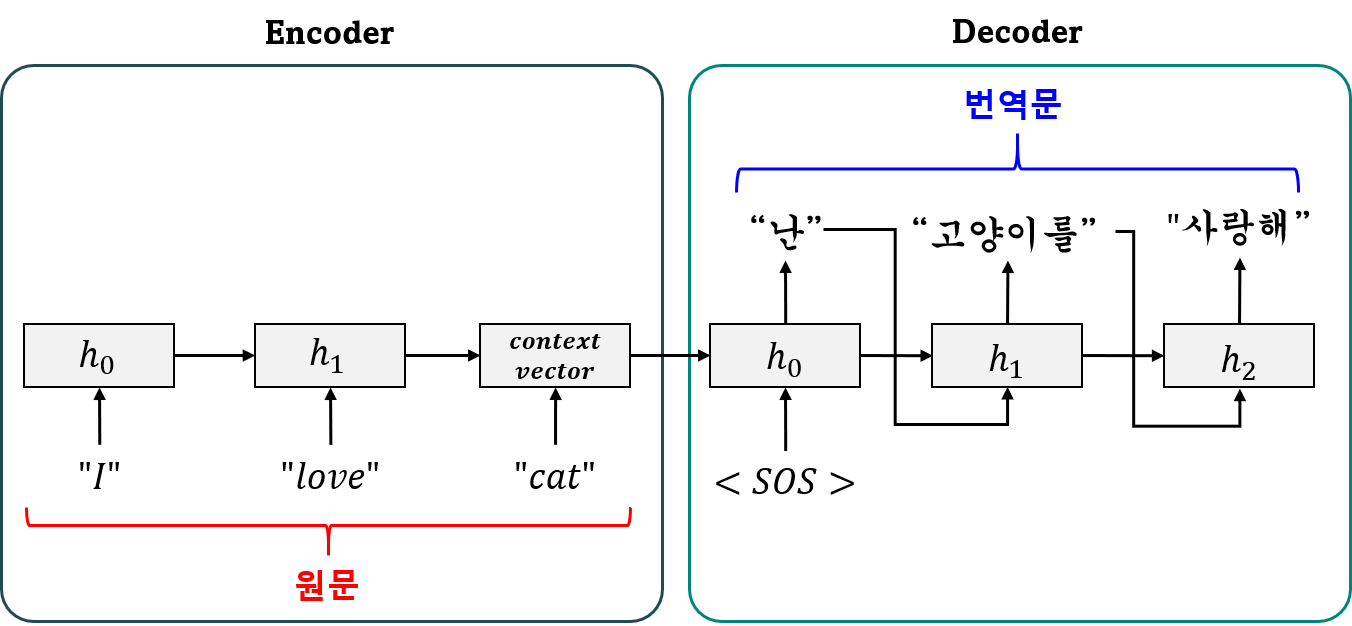
이 모델과 동일한 형태로 RNN은 앞서 사용한 GRU를, 입력 값으론 hello, 출력값으로는 hola를 예측하는 모델을 만들어보자.
- 사용 코드
yellowjs0304/3-min-pytorch_study
3분 딥러닝 파이토치맛 - 오픈소스 개인 스터디용. Contribute to yellowjs0304/3-min-pytorch_study development by creating an account on GitHub.
github.com
앞선 예제보다 훨씬 간단한 형태로 초반에 필요한 패키지를 정의한다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
import matplotlib.pyplot as plt #시각화
자세한 모델 정의 이전에 입력 데이터를 전처리하면 아래와 같다.
이때 기본적인 문장 번역, 또는 sequential data는 주로 여러 word가 합쳐진 sentence를 기반으로 동작하기 때문에 word embedding을 진행하지만, 본 예제에서는 철자 하나씩 다 예측하고 입력으로 넣기 때문에 character embedding을 수행하였다.
# 기본적으로는 문장을 넣기 때문에 Word Embedding을 진행하지만,
# 이 예제에서는 철자 하나씩에 대한 Character Embedding을 수행
vocab_size = 256 # 영문만 다루기 때문에, 영문에 대한 총 아스키 코드 개수
x_ = list(map(ord, "hello")) # 아스키 코드 리스트로 변환
y_ = list(map(ord, "hola")) # 아스키 코드 리스트로 변환
# x : 원문 / y : 번역문
print("hello -> ", x_)
print("hola -> ", y_)
# 모델 입력을 위해 Tensor형태로 변환
x = torch.LongTensor(x_)
y = torch.LongTensor(y_)
모델 클래스 정의는 아래와 같다. 우선, init함수부터 보면 크게 GRU로 된 Encoder, decoder가 정의되어 있으며, RNN의 입력이 될 hidden size와 간단한 모델이므로 n_layer를 1로 설정한다. embedding은 앞서 설명한 character embedding을 위한 임베딩 네트워크이다.
class Seq2Seq(nn.Module):
def __init__(self, vocab_size, hidden_size):
super(Seq2Seq, self).__init__()
self.n_layers = 1 # 간단하니깐
# hidden_size : 이번 예제에서는 별도의 값이 아닌, 임베딩된 토큰의 차원값과 동일히 정의
self.hidden_size = hidden_size
self.embedding = nn.Embedding(vocab_size, hidden_size)
self.encoder = nn.GRU(hidden_size, hidden_size)# 인코더 정의
self.decoder = nn.GRU(hidden_size, hidden_size)# 디코더 정의
self.project = nn.Linear(hidden_size, vocab_size)# 디코더가 번역문의 다음 토큰을 예상하는 Linear layer 정의
이후 forward함수를 이용해 앞서 그린 그림에서 보이듯 데이터의 흐름을 조작한다.
천천히 읽어보면 encoder에게 input data를 제공하고, 그때 생성된 encoder_state(context vector)를 decoder의 입력으로 넣어주게 된다. 또한, 문장의 시작 토큰(앞선 그림의 SOS토큰)을 NULL을 의미하는 [0]로 조작하여 decoder에게 같이 넣어준다.(SOS토큰은 실제 문장에서는 보이지 않고, decoder가 정상적으로 시작할 수 있게 넣어준 의미없는 토큰이다)
def forward(self, inputs, targets):
# 인코더에 들어갈 입력 임베딩
initial_state = self._init_state()
embedding = self.embedding(inputs).unsqueeze(1)
# embedding 형태: [seq_len, batch_size, embedding_size]
# 인코더 (Encoder)
encoder_output, encoder_state = self.encoder(embedding, initial_state)
# encoder_output = [seq_len, batch_size, hidden_size]
# encoder_state : 인코더의 context vector [n_layers, seq_len, hidden_size]
# 디코더에 들어갈 입력을 인코더의 context vector로 지정
decoder_state = encoder_state
decoder_input = torch.LongTensor([0])# 문장의 시작을 위해서 NULL을 의미하는 [0]으로 설정
# 디코더 (Decoder)
outputs = []
for i in range(targets.size()[0]):
decoder_input = self.embedding(decoder_input).unsqueeze(1)#임베딩 및 사이즈 맞추기 위해서 unsqueeze
# decoder 입력 : 초기 문장 시작(NULL), Encoder의 context vector
decoder_output, decoder_state = self.decoder(decoder_input, decoder_state)
# 디코더의 출력값으로 다음 글자 예측
projection = self.project(decoder_output)
outputs.append(projection)
# 티처 포싱(Teacher Forcing) 사용
# 디코더 학습 시 실제 번역문의 토큰을 디코더의 전 출력값 대신 입력으로 사용
decoder_input = torch.LongTensor([targets[i]])
# output : 모든 토큰에 대한 결괏값들의 배열
outputs = torch.stack(outputs).squeeze()
return outputs
def _init_state(self, batch_size=1):
weight = next(self.parameters()).data
return weight.new(self.n_layers, batch_size, self.hidden_size).zero_()대부분의 학습 과정은 이전과 동일한데, 이때 teacher forcing이라는 개념이 등장하게 된다.
- teacher forcing
: 주로 Seq2Seq 모델에서 등장하는 기법으로 RNN의 입력에 이전에 모델의 출력물을 넣어주지 않고, 정답 데이터를 넣어주는 것이라 보면 된다. 기존의 학습법이 상단 이미지처럼 직전의 모델 예측 결과물을 그대로 다음 input으로 주는 형태였다면, teacher forcing의 경우 모델의 예측 결과물은 무시하고 정답(target data==ground truth)를 모델의 입력에 넣는 모습이다.

기존의 학습법은 앞선 모델의 잘못된 입력이 뒤에까지 영향을 미치면서 학습을 진행하기까지 오랜 시간이 걸릴 수 있는 것을 teacher forcing에서 정답 데이터를 넣으면서 마치 선생님처럼 잘못된 부분을 교정하면서 가르치기 때문에 학습이 다소 빨리 될 수 있다.
이런 면만 보면 teacher forcing이 제일 좋아보이는 듯 하지만, teacher forcing은 아무래도 데이터 의존적인 학습이 발생할 수밖에 없고 일반화된 모델의 성능을 기대하기 어렵다는 단점이 있다.
개인적인 경험으로 teacher forcing을 사용하려면 적어도 수많은 데이터가 보장된 상태에서 초기 학습을 teacher forcing으로 진행하여 어느 정도 실력을 갖춘 모델을 생성하고, 추후 기존과 같은 방법(student forcing)을 적용하면서 변별력있는 데이터에도 대응할 수 있는 모델을 만드는 것이 좋은 방법인 것 같다.
# 모델 선언(Vocab_SIZE, hidden feature size)
seq2seq = Seq2Seq(vocab_size, 16)
# Loss : cross entropy loss
# Optimizer : Adam
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(seq2seq.parameters(), lr=1e-3)forward함수 정의가 끝나면 seq2seq 모델과 Loss, optimizer를 정의해주고
log = []
for i in range(1000):
prediction = seq2seq(x, y)
loss = criterion(prediction, y)
optimizer.zero_grad()# Optimizer 매번 계산하니깐 zero로 설정
loss.backward()
optimizer.step()
loss_val = loss.data
log.append(loss_val)
# 100 에폭마다 출력
if i % 100 == 0:
print("\n 반복:%d 오차: %s" % (i, loss_val.item()))
_, top1 = prediction.data.topk(1, 1)
print([chr(c) for c in top1.squeeze().numpy().tolist()])일정 반복에 따라서 학습을 진행하도록 한다. 이때 1000번 중 100번마다 결과값을 출력해주도록 한다.
실제로 학습을 진행해보면 아래처럼 나오게 된다.

처음 100만 했는데도 hola를 잘 예측하는 것으로 봐서 teacher forcing 때문에 상당히 빨리 된 것으로 추측된다.
이후 plt함수로 graph를 확인하면 아래와 같다.
# 학습이 지나면서 Loss가 줄어드는 것 확인 가능
plt.plot(log)
plt.ylabel('cross entropy loss')
plt.show()
'머신러닝 > Pytorch 딥러닝 기초' 카테고리의 다른 글
| [Pytorch-기초강의] 7. 딥러닝을 해킹하는 적대적 공격 (0) | 2021.06.13 |
|---|---|
| [Pytorch-기초강의] 6. 순차적인 데이터를 처리하는 RNN(LSTM, GRU) (0) | 2021.05.25 |
| [Pytorch-기초강의] 5. 사람의 지도 없이 학습하는 오토인코더(AutoEncoder) (0) | 2021.05.21 |
| [Pytorch-기초강의] 4. 이미지 처리 능력이 탁월한 CNN(Simple CNN, Deep CNN, ResNet, VGG, Batch Normalization ) (0) | 2021.05.14 |
| [Pytorch-기초강의] 4. 이미지 처리 능력이 탁월한 CNN(Convolution, kernel, Padding, Pooling) (0) | 2021.04.06 |