
본 포스팅은 앞에서 다룬 RNN내용의 심화 내용으로, 3분 딥러닝 교재에 없던 LSTM과 GRU 내용을 담은 포스팅이다.
RNN의 문제점
LSTM과 GRU가 나오게 된 배경으로, 기존 RNN에는 장기 의존성(Long-Term Dependency) 문제가 발생한다.
일반적인 RNN의 경우 아주 긴 문장을 입력해준다 가정하였을 때, 학습 도중에 기울기가 너무 작아지거나 커져서 앞부분에 대한 정보를 끝까지 가져오지 못할 확률이 높아진다. (Gradient vanishing/exploding)
아래 예제를 일반적인 RNN의 동작 방식은 $h_{t}$시점의 출력 결과가 이전의 $h_{t-1}$계산 결과에 의존한다. 다만, 이럴 경우 짧은 시퀀스(sequence)의 데이터에 대해서만 효과를 보이지, 긴 데이터의 경우 앞의 정보가 충분히 전달되지 못하고 매 순간 weight(0~1사이)를 곱하다보면 아래 그림의 색이 점차 옅어지는 것처럼 정보력이 소실된다.

만약 예제와 같이 앞부분에 중요한 정보가 있는 긴 문장일 경우, 기존 RNN을 사용할 시, BLANK 단어를 예측하기 위해 필요한 앞쪽 단어 정보를 기억하지 못하고 엉뚱한 "나는 저 여기" 라는 단어에 의존하여 예측할 수 있다.
이전 CNN 포스팅에서도 vanishing 문제를 해결하기 위해 ResNet을 도입했던 것처럼 RNN에서도 이 문제를 보완하기 위해 발전된 형태의 LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit)를 제안한다.
LSTM
LSTM은 1997년에 처음 제안한 RNN cell로서, 장기의존성 문제와 빠른 학습 속도를 자랑한다. LSTM의 특징은 Cell State로, Cell state는 이전의 hidden state와 함께 다음 레이어로 기존의 상태를 보존하여 전달해준다.
좌측이 기존의 RNN이라면, 우측처럼 다양한 함수, 처리과정이 추가된 LSTM을 확인할 수 있다.


LSTM은 크게 Forget, Input, Update, Output Gate 등의 구조로 나뉘며, 앞에서 언급했듯 $h_{t}$(단기 상태, short-term state), $c_{t}$(장기 상태, long-term state)이 다음 상태로 넘어가게 된다. 이때 $c_{t}$에서 어떠한 정보를 기억, 삭제, 읽어들일지를 학습하는 단계라 보면 된다. 자세한 세부 과정은 아래에서 차례로 살펴보자.
1. Forget Gate
: 과거의 정보를 얼마큼 버릴지 말지(가져와야 할지) 결정
- $f_{t}$는 과거의 정보에 대해서 얼마나 버릴까/갖고 갈까를 결정하는 값.
- $f_{t}$ 도 gate controller로, sigmoid($\sigma$)를 통해 0~1 사이의 값을 받게 된다.
- 값이 0에 가까울수록, 이전 cell state 값이 0에 가까워짐(==많은 정보를 잊어버림)
- 반대로, 1일 경우 완벽하게 이 값을 갖고 가자는 의미(==다음 cell state값에 영향을 줌.)
$f_{t}=\sigma(W_{f}\cdot [h_{t-1},x_{t}]+b_{f})$
$=\sigma(W_{xf}x_{t}+W_{hf}h_{t-1}+b_{f})$
- $W_{f}$: weight of layer
- $b_{f}$: bias of layer
- $W_{xf}$ : 입력 벡터 x_{t}에 연결된 레이어에 대한 weight matrix
- $W_{hf}$: 직전 timestep (t-1)시점의 hidden state($h_{t-1}$)에 연결된 레이어에 대한 weight matrix

2. Input Gate
: 현재 정보를 얼마큼 저장해야할지(버려야할지) 결정
- $+$덧셈 연산을 통해 Input Gate로부터 새로운 기억 일부를 추가하는 과정
- $i_{t}$는 신규 입력 데이터에 대해서 얼마나 버릴까/갖고 갈까를 결정하는 값.
- $i_{t}$도 gate controller로, sigmoid($\sigma$)를 통해 0~1 사이의 값을 받게 된다.
- 값이 0에 가까울 수록 신규 input data가 0에 가까워짐(==많은 정보를 잊게 됨)
- 반대로, 1일 경우 완벽하게 이 값을 갖고 가자는 의미(==다음 cell state값에 영향을 줌.)
$i_{t}=\sigma(W_{i}\cdot [h_{t-1},x_{t}]+b_{i})$
- $\tilde{C}_{t}$은 $g_{t}$라고도 표기되며, tanh를 통해서 -1~1사이의 값을 갖는다.
- 1에 가까울 수록 현재 정보를 최대한 많이 cell state에 더하자는 의미.
- -1에 가까울수록 현재 정보를 최소한으로 cell state에 더하자는 의미.
$\tilde{C}_{t}=\tanh(W_{C}\cdot [h_{t-1},x_{t}]+b_{C})$
$=\tanh(W_{xg}^{T}x_{t}+W_{hg}^{T}h_{t-1}+b_{g})$
- $W_{C}$: weight of layer
- $b_{g}, b_{C}$: bias of layer
- $W_{xg}$ : 입력 벡터 x_{t}에 연결된 레이어에 대한 weight matrix
- $W_{hg}$: 직전 timestep (t-1)시점의 hidden state($h_{t-1}$)에 연결된 레이어에 대한 weight matrix
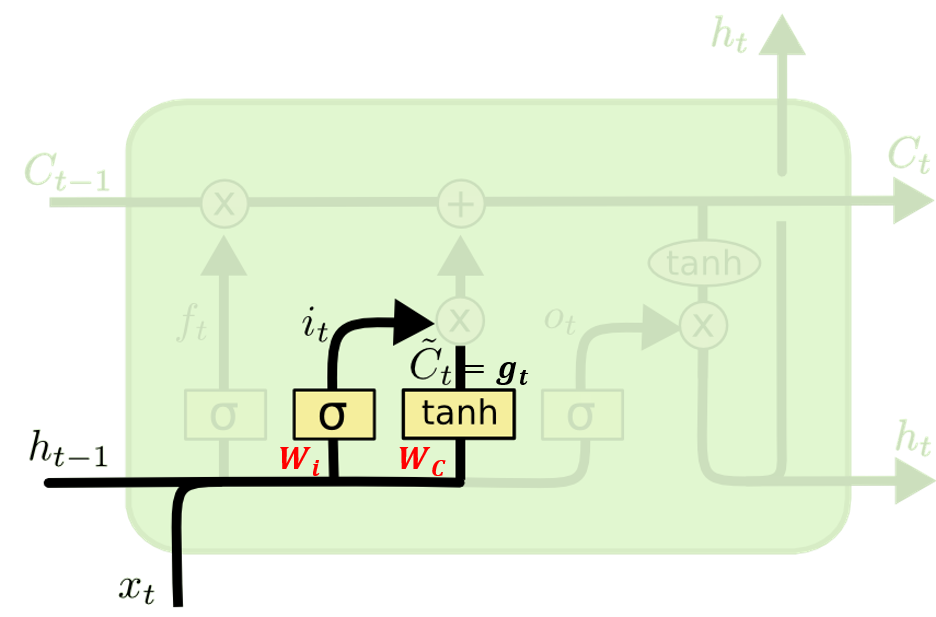
3. Update Gate
: 과거의 cell state를 새로운 state로 업데이트 하는 과정
- 과거 정보를 위한 $f_{t}$, 현재 정보를 위한 $i_{t}$와 $\tilde{C}_{t}$를 구한 후, 이들을 원소곱한다.
- $f_{t}\ast C_{t-1}$을 통해 이전 시점의 cell state를 얼마나 유지할지 계산할 수 있으며,
- $i_{t}\ast \tilde{C}_{t}$를 통해 현재 기억할 정보를 구함.
- 최종적으로 $C_{t}$를 앞서 구한 값을 서로 더해 update
$C_{t}=f_{t}\ast C_{t-1}+i_{t}\ast \tilde{C}_{t}$

4. Output Gate
: 최종적으로 우리가 얻은 cell state를 밖으로 얼마나 내보낼지 결정하는 역할.
- $O_{t}$는 현재 cell state의 얼마만큼을 $h_{t}$로 내보내야 할지 결정하는 역할
- hidden state는 현 시점의 cell state와 함께 계산되어 출력됨과 동시에 다음 state로 넘겨짐.
$O_{t}=\sigma(W_{o}\cdot [h_{t-1},x_{t}])$
$=\sigma(W_{xo}x_{t}+W_{ho}h_{t-1}+b_{o}) $
$h_{t}=o_{t}\ast tanh(c_{t})$
- $W_{o}$: weight of layer
- $b_{o}$: bias of layer
- $W_{xo}$ : 입력 벡터 x_{t}에 연결된 레이어에 대한 weight matrix
- $W_{ho}$: 직전 timestep (t-1)시점의 hidden state($h_{t-1}$)에 연결된 레이어에 대한 weight matrix

Tensorflow일 경우, 아래와 같은 코드로 LSTM을 구현해줄 수 있음.
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=n_neurons)
Pytorch일 경우, 아래와 같은 코드로 LSTM을 구현해 줄 수 있음.
import torch.nn as nn
lstm = nn.LSTM(input_size=n_class, hidden_size=n_hidden, dropout=DROPOUT_RATE)예제 외 각각의 하이퍼파라미터는 상단 링크로 넘어가 직접 살펴보기 바란다.
+) PeepHole Connection
2000년에 F. Gers와 J.Schmidhuber가 'Recurrent Nets that and Count' 논문에서 제안한 LSTM의 변종이다.
기존의 LSTM이 각 gate의 controller로써 $f_{t}, i_{t}, o_{t}$를 사용해 입력 정보와 직전 hidden state만을 입력으로 사용하였다면, 여기서는 아래 그림처럼 직전 (t-1)시간의 cell state를 입력으로 추가하여 이전보다 더 많은 양의 맥락정보(context information)를 유지하고자 하는 모델이다. 개인적으로 실제 과제를 진행하면서 peephole connection 모델을 잘 사용해보진 않았고, 오히려 bidirectional LSTM을 쓰는게 가장 성능 상 좋았다(물론 당연한거지만)

lstm_cell = tf.nn.rnn_cell.LSTMCell(num_units=n_neurons, use_peepholes=True)
# BasicLSTMCell 대신에 LSTMCell로 변경
GRU
GRU는 2014년에 처음 제안한 LSTM의 간소화된 버전으로 기존 LSTM이 너무 복잡하고 연산량이 많아 개선한 모델이다.

LSTM의 forget gate와 input gate를 하나의 update gate로 합치고, cell state와 hidden state를 합쳤다.
1. Reset Gate
: 새로운 입력 정보를 이전 메모리와 어떻게 합칠지 결정하는 단계
(== 이전 hidden state에서 얼마큼 값을 반영해줄지)
- $r_{t}$ : LSTM과 달리 output gate가 없어, 전체 상태 벡터라 할 수 있는 hidden state가 매 타임스텝마다 출력되며, 직전 hidden state의 어느 부분이 출력될지를 제어
- 직전 시점의 hidden state($h_{t-1}$)와 현 입력 정보($x_{t}$)의 activation function(sigmoid)을 적용하여 구함.
$r_{t}= \sigma (W_{r}\cdot [h_{t-1},x_{t}])$
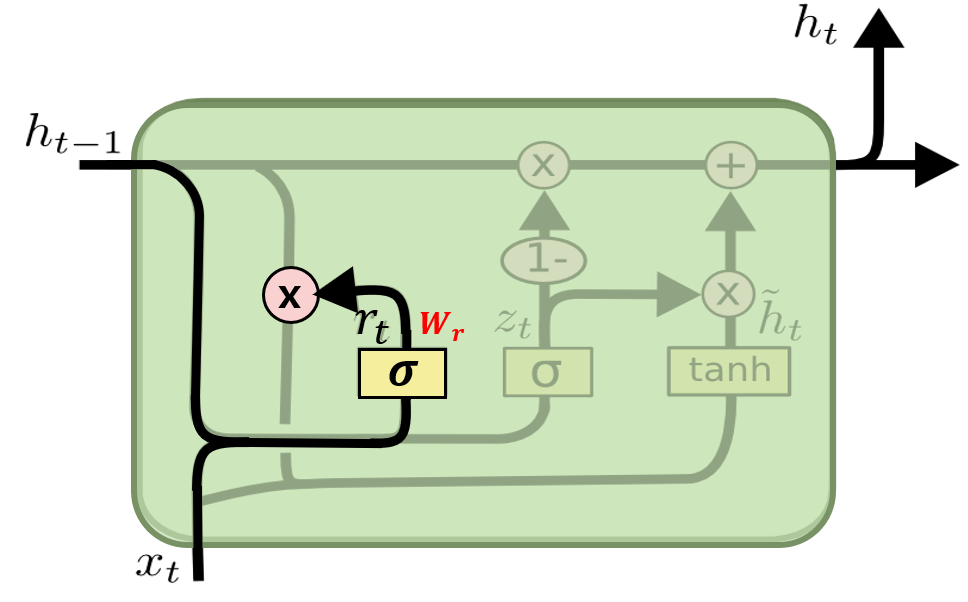
2. Update Gate
: LSTM의 forget gate와 input gate를 합친 과정, 과거, 현재 정보를 각각 얼마나 반영할지 비율을 구하는 단계
- $\tilde{h}_{t}$은 reset gate를 사용하여 임시 $\tilde{h}_{t}$를 만든다.
- $z_{t}$은 현재 입력 정보를 얼마나 사용할지 반영하는 양을 결정하며,
- $h_{t}$은 $(1-z_{t})$를 통해 과거 정보를 얼마나 사용할지 반영하고, 최종 hidden state(출력값)을 구한다.
$\tilde{h}_{t}=tanh(W_{h}\cdot [r_{t}\ast h_{t-1}, x_{t}])$
$z_{t}=\sigma(W_{z}\cdot [h_{t-1},x_{t}])$
$h_{t}=(1-z_{t})\cdot h_{t-1}+z_{t}\cdot \tilde{h}_{t}$

GRU는 LSTM에 비해서 상당히 간단한 구조를 갖고 있으며, 마지막 최종 출력으로 activation function을 사용하지 않는다. 성능면에서는 LSTM과 비교했을 때 더 우월하진 않지만, 학습할 파라미터가 훨씬 적다.
Tensorflow일 경우, 아래와 같은 코드로 GRU를 구현해줄 수 있음.
gru_cell = tf.nn.rnn_cell.GRUCell(num_units=n_neurons)Pytorch일 경우, 아래와 같은 코드로 GRU를 구현해 줄 수 있음.
import torch.nn as nn
lstm = nn.GRU(embed_dim, self.hidden_dim,num_layers=self.n_layers, batch_first=True)예제 외 각각의 하이퍼파라미터는 상단 링크로 넘어가 직접 살펴보기 바란다.
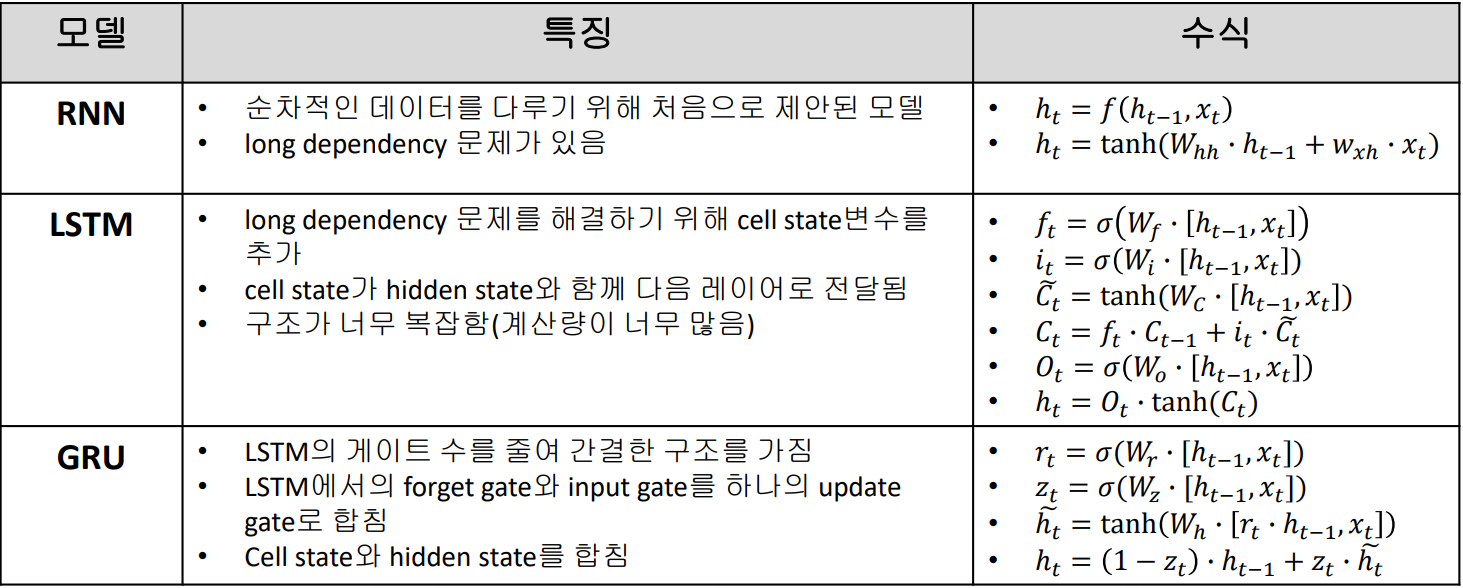
종합
참고 포스팅 : https://blog.naver.com/jaeyoon_95 / https://excelsior-cjh.tistory.com/185 / https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=winddori2002&logNo=221992543837
'머신러닝 > Pytorch 딥러닝 기초' 카테고리의 다른 글
| [Pytorch-기초강의] 8. 경쟁하며 학습하는 GAN (3) | 2021.06.13 |
|---|---|
| [Pytorch-기초강의] 7. 딥러닝을 해킹하는 적대적 공격 (0) | 2021.06.13 |
| [Pytorch-기초강의] 6. 순차적인 데이터를 처리하는 RNN (0) | 2021.05.25 |
| [Pytorch-기초강의] 5. 사람의 지도 없이 학습하는 오토인코더(AutoEncoder) (0) | 2021.05.21 |
| [Pytorch-기초강의] 4. 이미지 처리 능력이 탁월한 CNN(Simple CNN, Deep CNN, ResNet, VGG, Batch Normalization ) (0) | 2021.05.14 |