
※ 본 게시물에 사용된 내용의 출처는 대다수 <펭귄브로의 3분 딥러닝-파이토치맛>에서 사용된 자료이며, 개인적인 의견과 해석이 추가된 부분도 존재합니다. 그림의 경우 교재를 따라 그리거나, 제 임의대로 추가 수정한 부분도 존재합니다. 저 역시도 공부하고자 포스팅한 게시물이니, 잘못된 부분은 댓글로 알려주시면 감사하겠습니다.
- Supervised learning / Unsupervised learning
- AutoEncoder
Supervised vs Unsupervised Learning
이전까지 다뤘던 분류 모델들은 대다수 정답이 존재하는 데이터들로, 지도 학습(Supervised learning)을 가능케 하는 문제들이다. 하지만, 대다수 실세계의 수집 데이터는 특정 정답이 없으며, 단순히 주어진 데이터들을 구분할 수 있는 특정 패턴을 찾아야만 한다. 이 과정이 비지도 학습(Unsupervised learning)이다. 일전의 포스팅에서 이미 비지도 학습, 지도 학습에 대한 정의를 간단히 다룬 적이 있다. 각각의 정의는 아래와 같고 아래 그림을 보면 더 이해하기 쉽다.
- Supervised learning : 데이터-데이터 라벨(입력 - 출력)쌍이 미리 정의된 데이터로 학습하는 경우
좌측 그림처럼 데이터와 그에 맞는 정답클래스를 명시해 둔 데이터로 네트워크를 학습하는 것을 의미한다. 이후 분류 작업에서 학습했던 내용을 바탕으로 실제 클래스를 예측한다.
- Unsupervised learning : 데이터-데이터 라벨(입력 - 출력)쌍이 정의되지 않은 데이터로 학습하는 경우
우측 그림의 경우, 정답이 주어지지 않은 무더기의 데이터들을 주고, 알아서 학습하면서 비슷한 데이터끼리 모아서 군집화(클러스터링, Clustering)를 할 수 있도록 학습을 진행한다.
+) Clustering(군집화) : 명확히 구분되지 않는 데이터들을 비슷한 특징을 갖는 데이터끼리 묶어주는 것.
대표적인 clustering 알고리즘 : K-means algorithm, Mean Shift Algorithm ...

AutoEncoder
AutoEncoder(오토 인코더)모델은 비지도학습을 진행하는 대표 네트워크 다음과 같은 특징을 갖고 있다.
- 입력과 출력이 같은 구조
- 병목 구조(Bottleneck layer = Latent variable, Feature, Hidden representation)
- Encoder-Decoder 구조
+) Encoder : 입력 데이터를 받아 압축 , Decoder : 압축된 표현을 풀어 출력물을 생성
- 처리 과정:
1) Input Data를 Encoder Network에 넣어, 압축된 특징 벡터 z (회색 노드, latent variable)를 생성.
2) 압축된 z벡터로부터 Decoder Network를 통해 Input과 유사한 Output Data를 생성.

오토 인코더는 정답이 없는 x 데이터만으로 의미를 추출하기 위하여 x를 입력받아 다시 x를 복원할 수 있는 신경망을 학습하는 것이 핵심이다. 입력 데이터와 유사한 결과물을 만들려면 자연스레 네트워크에는 해당 입력 데이터의 의미있는 정보들이 쌓이게 되고, 실제 복원한(예측한) 결과물을 원본데이터와 비교하며 얼마나 비슷한지 근사치를 출력해내기 때문에 Reconstruction Loss(복원 오차, 정보 손실값)이 Loss가 되어 네트워크 학습에 사용된다. 이 과정에는 예제에 넣어둔 것 처럼 cross entropy loss나 L1, L2 loss값도 쓰인다.
+) L1 loss : 실제-예측값 간 차이의 절댓값 / L2 loss(=Mean Squared Error): 오차의 제곱합
오토 인코더의 핵심은 입력, 출력의 크기는 같지만 중간으로 갈 수록 신경망의 차원이 줄어들면서, 입력 특징이 압축되는 잠재 변수(latent variable)를 얻을 수 있게 된다. 이 압축 데이터는 의미(context, semantic...)의 압축이 일어나게 되며 이는 단순히 사이즈를 줄이는 압축이 아닌, 중요한 정보만을 담는다는 압축을 의미한다. 이는 다른 의미론 필연적으로 불필요한 정보에 대해 정보 손실과정이 일어난다는 의미로 볼 수 있다.
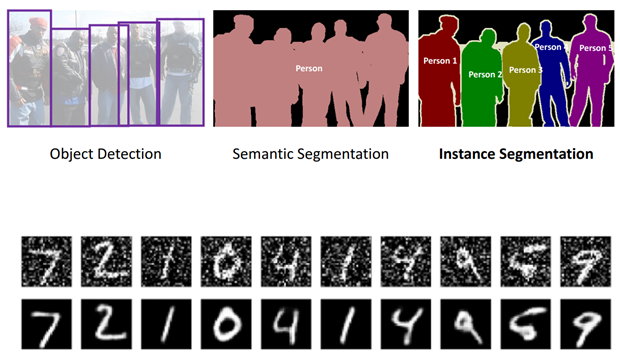
오토 인코더는 주로 복잡한 비선형 데이터의 차원을 줄이는 용도로 쓰이며, 비정상적 거래 검출, 데이터 시각화-복원, 의미 추출, 이미지 검색 등에 사용되기도 한다. 또한, 아래 사진처럼 이미지를 의미있는 부분으로 모든 픽셀에 대하여 예측할 수 있는 Semantic Segmentation 과정이나 이미지의 노이즈를 제거하는 Noise Reduction 과정에도 활용될 수 있다.
오토인코더 이미지 생성 예제
- 사용 코드
yellowjs0304/3-min-pytorch_study
3분 딥러닝 파이토치맛 - 오픈소스 개인 스터디용. Contribute to yellowjs0304/3-min-pytorch_study development by creating an account on GitHub.
github.com
본 예제에서는 FashionMNIST 데이터셋을 이용해 AutoEncoder모델을 학습시키는 예제를 진행하고자 한다.
import torch
import torchvision
import torch.nn.functional as F
from torch import nn, optim
from torchvision import transforms, datasets
import matplotlib.pyplot as plt # Matplotlib: 이미지 출력을 돕는 모듈
from mpl_toolkits.mplot3d import Axes3D # Axes3D: Matplorlib에서 3차원 plot을 그리는 용도
from matplotlib import cm # Data 포인트에 색상입히는 용도
import numpy as np # Numpy 행렬 변환준비를 위해 필요한 패키지는 다음과 같다. 이전에 비해서 시각화 결과물을 보여주기 위해 matplotlib를 추가하였다.
# 하이퍼파라미터
EPOCH = 50
BATCH_SIZE = 64
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
print("Using Device:", DEVICE)
# Fashion MNIST 데이터셋 다운로드 및 데이터로더 선언
trainset = datasets.FashionMNIST(
root = './.data/',
train = True,
download = True,
transform = transforms.ToTensor()
)
train_loader = torch.utils.data.DataLoader(
dataset = trainset,
batch_size = BATCH_SIZE,
shuffle = True,
num_workers = 2
)교재에는 Epoch이 10으로 되어 있는데, 시각화된 결과물로 봤을 때 큰 성능 향상이 없는 것 같아 Epoch을 50으로 수정하고 돌려본 결과를 기입하였다. 그 외 데이터 로딩 과정은 이전과 동일한데, 이때 다른 모델과 달리 test set이 없는 것을 알 수 있다.
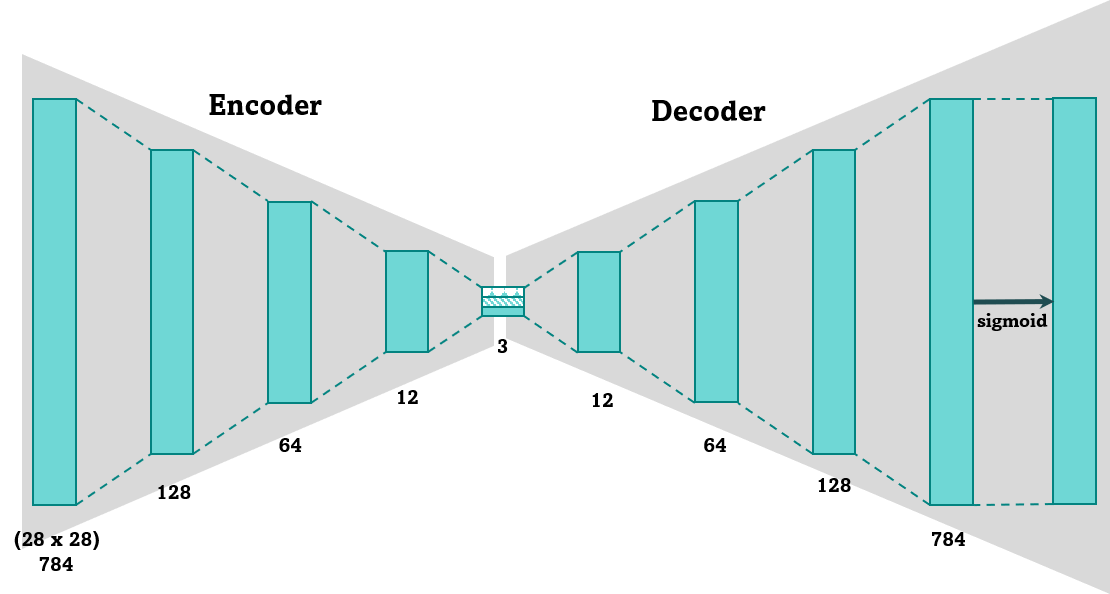
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 12),
nn.ReLU(),
nn.Linear(12, 3), # 입력의 특징을 3차원으로 압축합니다
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(),
nn.Linear(12, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28*28),
nn.Sigmoid(), # 픽셀당 0과 1 사이로 값을 출력합니다
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded본격적인 AutoEncoder클래스를 정의해보자. 모델은 nn.Sequential을 이용하여 크게 Encoder(self.encoder), Decoder(self.decoder) 두 개의 모듈로 구성되어 있으며 각 모델은 대칭되는 구조로 구현되어 있다. 이때 Encoder의 시작 layer와는 입력 이미지(FashionMNIST 이미지 크기 : 28x28)를 처리하는 레이어로써, nn.Linear(28*28, 128) 가 적용되어 있으며, Encoder단에서는 128 -> 64 -> 12 -> 3의 순으로 특징 벡터가 줄어드는 것을 알 수 있다. 인코더의 출력 레이어(nn.Linear(12, 3))를 통해 3차원 형태의 잠재 변수(Z)를 생성되는 것을 알 수 있고 이후 Decoder가 해당 Z를 입력받아 역순의 형태로 3 -> 12 -> 64 ->128로 특징 벡터를 확장하며, Decoder의 출력 layer(nn.Linear(128, 28*28))로 입력과 동일한 이미지를 출력함을 알 수 있다.
유일한 차이점은 마지막 출력값을 0~1사이로 만드는 Sigmoid함수가 더해지는 것 뿐이다.
데이터의 forward함수는 매우 간단하며, 입력으로 들어온 X 데이터를 받아 Encoder의 출력물(encoded)을 만들고, 이를 다시 decoder의 입력으로 주어 decoded를 생성하는 것을 알 수 있다.
autoencoder = Autoencoder().to(DEVICE)
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=0.005)
#최적화 함수 : Adam() --> SGD의 변형, 학습중인 기울기를 참고하여 학습 속도를 자동으로 변화
criterion = nn.MSELoss()
# MSE(Mean Squared Error) : 평균 제곱 오차
# 원본 이미지를 시각화 하기 (첫번째 열)
view_data = trainset.data[:5].view(-1, 28*28)
view_data = view_data.type(torch.FloatTensor)/255.실제 학습과정에 사용될 optimizer로 SGD의 변형 함수인 Adam을 적용하여 학습중인 기울기를 참고하여 학습 속도를 자동으로 변화할 수 있도록 정의하였다. Loss(criterion)로는 MSE(Mean Squared Error)로 실제 디코더에서 나온 값과 원본 간의 차이를 계산하기 위해 평균 제곱오차를 Loss함수로 사용하도록 하였다.
이 예제에서는 Epoch이 완료될 때마다 복원이 어떻게 되는지 확인하고자 한다. 매 번 모델의 Input으로 데이터셋 내 특정 5개의 이미지를 갖고와 모델에 바로 넣을 수 있도록 전처리 한 단계가 view_data생성과정이다.
def train(autoencoder, train_loader):
autoencoder.train()
for step, (x, label) in enumerate(train_loader):
x = x.view(-1, 28*28).to(DEVICE)
y = x.view(-1, 28*28).to(DEVICE)
label = label.to(DEVICE)
encoded, decoded = autoencoder(x)
loss = criterion(decoded, y)
#실제 예측한 값(decoded), 정답(y)간의 Loss 계산
optimizer.zero_grad()
loss.backward()
optimizer.step()
for epoch in range(1, EPOCH+1):
train(autoencoder, train_loader)
# 디코더에서 나온 이미지를 시각화 하기 (두번째 열)
test_x = view_data.to(DEVICE)
_, decoded_data = autoencoder(test_x)
# 원본과 디코딩 결과 비교해보기
f, a = plt.subplots(2, 5, figsize=(5, 2))
print("[Epoch {}]".format(epoch))
for i in range(5):
img = np.reshape(view_data.data.numpy()[i],(28, 28))
a[0][i].imshow(img, cmap='gray')
a[0][i].set_xticks(()); a[0][i].set_yticks(())
for i in range(5):
img = np.reshape(decoded_data.to("cpu").data.numpy()[i], (28, 28))
a[1][i].imshow(img, cmap='gray')
a[1][i].set_xticks(()); a[1][i].set_yticks(())
plt.show()이후 학습에 사용할 train함수를 정의하고, 실제 epoch마다 시각화 하도록 plt함수를 같이 정의해주었다.
아래 이미지가 실제 학습 과정에서 출력되는 이미지 이며, Epoch 1과 Epoch 50의 차이를 확인해보자.
둘 다 상단이 실제 데이터셋 이미지이고, 아래가 예측한 이미지이다. Epoch 50일때 경계선이 조금 더 뚜렷해짐을 알 수 있다.


이후, 실제 학습을 통해 생성된 잠재 변수가 어떻게 생겼는지 확인하기 위해 3차원 분포 시각화 함수를 정의하였다.
각 잠재변수마다 레이블을 붙이기 위하여 Dictionary를 정의하고 Axes3D함수로 3차원 형태의 액자를 만들어 각 차원 X, Y, Z를 따로 추출한 후 Numpy행렬화 하였다.

상단 이미지가 실제 시각화한 잠재변수이며, 이 이미지는 케이스마다 서로 다르게 표현될 수 있다.
하지만 확실히 흥미로운 점을 몇가지 알아보자면, 비슷한 레이블을 갖는 이미지의 잠재변수는 서로 모여 있다는 것을 알 수 있을 것이다. 각 레이블끼리 비슷한 색상끼리 묶여있음을 알 수 있으며, 여기에 더하여 Ankle boots, Sneakers, Sandal과 같이 신발과 관련된 변수들은 서로 공간적으로 가깝게 자리하고, 반대로 T-shirts/top, coat, dress, trouser와 같은 상의류도 서로 가깝게 겹친다는 것을 알 수 있다.
오토인코더 노이즈 제거 예제
- 사용 코드
yellowjs0304/3-min-pytorch_study
3분 딥러닝 파이토치맛 - 오픈소스 개인 스터디용. Contribute to yellowjs0304/3-min-pytorch_study development by creating an account on GitHub.
github.com
이번 예제는 앞에서 설명했던 모델과 큰 구조적 차이는 없고 단순히 학습 과정에 입력 데이터로 Noise를 추가하고 이를 복원할 수 있도록 조금 더 고도화한 모델이다.
다른 코드는 다 동일하고 일부 차이 있는 부분만 적어보면 아래 add_noise가 가장 큰 차이이다.
def add_noise(img):
noise = torch.randn(img.size()) * 0.2
noisy_img = img + noise
return noisy_img단순히 이미지에 무작위로 잡음을 더하여 image numpy행렬에 노이즈 행렬값을 더함으로써 기존 이미지를 훼손시킨다. (여기서 노이즈 강도는 0.2로 설정)
이후 train함수에서 입력에 노이즈를 더하는 한 줄만 추가하여, 그대로 학습을 진행한다.
def train(autoencoder, train_loader):
autoencoder.train()
avg_loss = 0
for step, (x, label) in enumerate(train_loader):
noisy_x = add_noise(x) # 입력에 노이즈 더하기
noisy_x = noisy_x.view(-1, 28*28).to(DEVICE)
y = x.view(-1, 28*28).to(DEVICE)
label = label.to(DEVICE)
encoded, decoded = autoencoder(noisy_x)
loss = criterion(decoded, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item()
return avg_loss / len(train_loader)여기서는 시각화 과정은 건너뛰고, 학습 중 변화하는 평균 오차값을 찍어보도록 했다.
Epoch은 10으로 설정했고, 점점 학습이 진행되면서 오차도 줄어드는 것을 확인할 수 있다.

이제 모델 학습이 다 완료되었으므로, 실제로 모델이 Train과정에서 본 적 없는 Test 이미지에 대하여 노이즈를 얼마나 제거할 수 있는지 테스트하기 위해 아래 코드를 추가하고 실제 모델의 성능을 관찰해보자.
# 모델이 학습시 본적이 없는 데이터로 검증하기 위해 테스트 데이터셋을 가져옵니다.
testset = datasets.FashionMNIST(
root = './.data/',
train = False,
download = True,
transform = transforms.ToTensor()
)
# 테스트셋에서 이미지 한장을 가져옵니다.
sample_data = testset.data[0].view(-1, 28*28)
sample_data = sample_data.type(torch.FloatTensor)/255.
# 이미지를 add_noise로 오염시킨 후, 모델에 통과시킵니다.
original_x = sample_data[0]
noisy_x = add_noise(original_x).to(DEVICE)
_, recovered_x = autoencoder(noisy_x)
f, a = plt.subplots(1, 3, figsize=(15, 15))
# 시각화를 위해 넘파이 행렬로 바꿔줍니다.
original_img = np.reshape(original_x.to("cpu").data.numpy(), (28, 28))
noisy_img = np.reshape(noisy_x.to("cpu").data.numpy(), (28, 28))
recovered_img = np.reshape(recovered_x.to("cpu").data.numpy(), (28, 28))
# 원본 사진
a[0].set_title('Original')
a[0].imshow(original_img, cmap='gray')
# 오염된 원본 사진
a[1].set_title('Noisy')
a[1].imshow(noisy_img, cmap='gray')
# 복원된 사진
a[2].set_title('Recovered')
a[2].imshow(recovered_img, cmap='gray')
plt.show()차근히 읽어보면 FashionMNIST의 test셋을 불러온 후, 그 testset중 이미지 한 장을 갖고와 모델의 입력이 될 수 있도록 전처리 하는 단계가 sample_data 정의부이다. 이후, add_noise함수로 동일하게 노이즈를 주고, autoencoder의 입력으로 (noisy_x)를 줬을 때 복원된 값을 recovered_x로 받는다. plt함수로 시각화를 주고, 관찰해보면 아래 이미지처럼 어느 정도 노이즈를 추가한 이미지에 대하여 원본 이미지만큼 복원하는 것을 알 수 있다.

'머신러닝 > Pytorch 딥러닝 기초' 카테고리의 다른 글
| [Pytorch-기초강의] 6. 순차적인 데이터를 처리하는 RNN(LSTM, GRU) (0) | 2021.05.25 |
|---|---|
| [Pytorch-기초강의] 6. 순차적인 데이터를 처리하는 RNN (0) | 2021.05.25 |
| [Pytorch-기초강의] 4. 이미지 처리 능력이 탁월한 CNN(Simple CNN, Deep CNN, ResNet, VGG, Batch Normalization ) (0) | 2021.05.14 |
| [Pytorch-기초강의] 4. 이미지 처리 능력이 탁월한 CNN(Convolution, kernel, Padding, Pooling) (0) | 2021.04.06 |
| [Pytorch-기초강의] 3. 패션 아이템을 구분하는 DNN(Overfitting, Dropout) (0) | 2021.02.15 |