
※ 본 게시물에 사용된 내용의 출처는 대다수 <펭귄브로의 3분 딥러닝-파이토치맛>에서 사용된 자료이며, 개인적인 의견과 해석이 추가된 부분도 존재합니다. 그림의 경우 교재를 따라 그리거나, 제 임의대로 추가 수정한 부분도 존재합니다. 저 역시도 공부하고자 포스팅한 게시물이니, 잘못된 부분은 댓글로 알려주시면 감사하겠습니다.
+) 본 포스팅은 기초 RL 용어는 알고 있다는 전제 하에 작성하였습니다. RL에 대한 기초적인 정보는 다른 포스팅을 참고해주시기 바랍니다.
Model-Based Algorithm vs Model-Free Algorithm
Model-based algorithm : 환경에 대해 이미 다 알고 학습
- 환경(environment)에 대해 알고 있고, 행동에 따른 환경 변화를 아는 알고리즘
- 어떤 state에서 어떤 action이 최고의 reward를 주는지 알 수 있음.
- Environment에 대해 이미 다 알고 있고, Exploration이 필요없음.
+) Exploration: 새롭고 다양한 상태-행동 공간을 방문하는 것(일종의 초기에 데이터 쌓기)
Model-Free algorithm : 환경을 모르고, 수동적인 학습
- Environment에 대해서 모르고, Action에 따른 다음 state와 reward를 수동적으로 외부로부터 받음.
- Environment를 모르기 때문에 Exploration을 통한 Trial and Error로 Policy Function을 점차 학습해야 함.
- 미래에 대해 최대 예측 reward를 최대로 하기 위한 policy function을 구하는 것이 목표.
Q-Learning
Q-Learning
대표적인 Model-Free algorithm으로 Finite Markov Decission Process(FMDP)를 기반으로 Agent가 특정 상황에서 특정 행동을 하라는 최적의 policy를 배우는 것으로, 현 state로부터 시작해 모든 sequential 단계를 거쳤을 때 전체 reward의 예측값을 최대화 할 수 있도록 한다.
Q Value : 특정 상태 $s$에서 어떤 행동 $a$를 수행했을 때, 해당 행동의 가치(Value)를 나타내는 함수$Q(s,a)$
= 행동-가치 함수(이전 포스팅 참고), 미래의 reward를 계산하기 위해서 0~1 사이의 감가율(discount factor)을 적용

간단히 예제로 이해하자면, 아래와 같은 Maze game을 예로 들 수 있다.

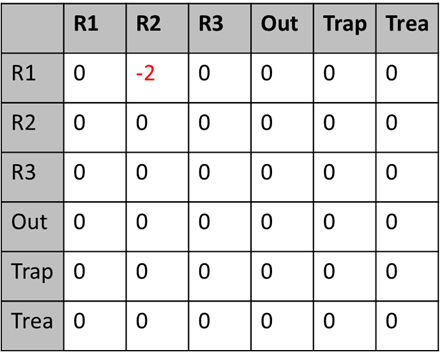
다음 예제처럼 매번 이동할때마다 reward를 주고 그에 따른 Q-function을 나타내라 한다면 일종의 표채우기처럼 생각해도 좋다. 초기에 1) Table을 모두 0으로 초기화 하거나, 2) 랜덤 값으로 초기화 하는 두가지의 방법이 존재하며, 에이전트가 경험을 쌓아가면서 일정 주기마다 q값(상태, 행동 별 평가 점수)을 수십번 갱신하면서, 최종적으로 최적의 q-value table을 만들어나가는 것이 가장 큰 목적이다. +) 그러다보니, 초반에는 단순히 경험을 쌓기 위한 exploration이 필수적이라 할 수 있다.


DQN(Deep Q-Network)
2013년 딥마인드에서 Atari 게임을 강화학습을 이용하여 플레이하는 논문을 냈는데, 거기서 등장한 것이 DQN이라 할 수 있다. 이 논문에서 DQN은 Atari의 대표 게임 몇 종류를 적은 정보만을 갖고 기존 알고리즘보다도 월등한 성능을 냈으며, 특정 게임에서는 버그를 찾아 치사한 방법으로 이기는 모습도 보여줬다. 그만큼, 사람보다도 어떤 면에서는 월등한 성능을 내기도 한다.
+) Atari Game

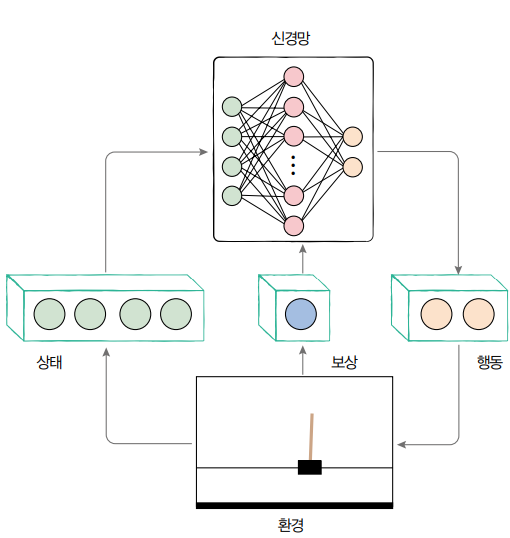
DQN의 핵심은 기존의 Q-learning알고리즘을 신경망으로 변경한것으로, 기존의 Q-learning이 Q-Table을 만들어나가는 과정이라면, DQN은 해당 Table을 Network로 대체한 것이다. 앞에서 본 q-learning 예제처럼 단순히 상하좌우 와 같이 Action의 개수가 한정적이고 적은 개수라면 Q-table을 만들어가는 것도 나쁘지 않을 수 있다. 다만, Robot 시스템이나 게임과 같이 무한하다 할 수 있을만큼 수많은 Action이 존재하는 환경에서는 모든 case에 다 맞춰 Q-table을 최적화한다는 것은 불가능에 가깝다. 이렇기 때문에 Network로 Q-table을 대체한 DQN이 등장하게 된다.
복잡한 수식 베이스의 이해보다는 실제 예제를 통해서 이해하는 것이 더 간단하므로, 바로 예제로 넘어가보자.
본 예제에서는 OpenAI Gym 내 Cartpole 예제를 사용해보도록 한다. Cartpole 게임은 막대기를 세우고 오래 버틸수록 점수가 올라가는 게임으로 카트를 좌, 우로 움직이면서 중심을 맞춰줘야 하는 게임이다.

State : [카트의 위치, 카트의 속력, 막대기 각도, 막대기 상단의 속도]
Action : [좌, 우]
DQN의 주요 특징은 Memorize(기억하기), Replay(다시 보기)로, DQN이 나오기 이전 신경망을 강화학습에 적용하면서 몇 가지 문제가 발생한 것을 개선하는 방법이다. 기존의 문제점은 다음과 같다.
1. 기존의 딥러닝 모델은 일반적인 학습 데이터 샘플이 각각 독립적이라 가정하지만, 강화학습은 연속된 state에 따라 의존적인 케이스로, state간의 상관관계가 크다. 이는 즉, 학습이 그만큼 더 어렵다는 것을 의미한다. 따라서 이전의 다른 케이스들과 다르게 무작위(랜덤)하게 가져오지않고, 연속된 경험을 학습할 때 초반의 몇 가지의 경험 패턴에만 치중하게 되면서 최적의 행동 패턴을 찾기 어렵다는 단점이 있다.
2. 새로운 경험을 이전 경험에 겹쳐쓰게 되면서 쉽게 잊어버린다.
==> "Memorize"기능 등장.
DQN의 memorize : 한마디로, 과거의 기억을 활용하자! 라는 취지로 이전에 경험한 것을 모두 배열에 담아 지속적으로 재학습하며, 신경망이 잊어버리지 않도록 한다는 아이디어이다. 기억해둔 경험들은 학습 과정에서 무작위로 뽑아 경험간의 상관관계를 줄일 수 있도록 한다. (개인적으로 Episode단위로 잘라서 학습을 한다 생각하면 좋을 것 같다. 이전이 Episode1, 2를 연속으로 뽑아가며 학습할 경우, 자꾸 Episode 1 --> 2로 넘어갈때의 영향력이 모델 학습에 영향을 미치게되며, 최적의 행동 패턴을 찾기 어렵기 때문에) 각 경험은 상태, 행동, 보상 을 담고 있어 마치 아래와 같은 배열또는 클래스로 만들어둔다. 본 예제에서는 Queue 자료구조를 사용할 예정이다. 좀 더 자세한 코드를 수반한 설명은 아래에서 다룬다.
self.memory = [(상태, 행동, 보상, 다음 상태)...]
DQN의 Replay : 이전 경험들을 모아놨으면 반복적으로 학습해야 한다. DQN agent가 기억하고 다시 상기하는 과정으로, experience-replay라고도 한다. 앞 서 설명했듯, 경험들을 무작위로 가져오면서 각 경험 샘플의 상관성을 줄일 수 있으므로, 보다 일반화된 모델 성능을 얻을 수 있다.
자세한 과정은 아래 예제 코드를 보면서 확실하게 정리해보자.
Cartpole 게임 (DQN 예제)
- 예제 코드
yellowjs0304/3-min-pytorch_study
3분 딥러닝 파이토치맛 - 오픈소스 개인 스터디용. Contribute to yellowjs0304/3-min-pytorch_study development by creating an account on GitHub.
github.com
필수 모듈 Import
import gym # 카트폴같은 여러 게임 환경 제공 패키지
# pip install gym 으로 설치 가능#
import random # 에이전트가 무작위로 행동할 확률을 구하기 위함.
import math # 에이전트가 무작위로 행동할 확률을 구하기 위함.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from collections import deque
#Deque : 먼저 들어온 데이터가 먼저 나가는 FIFO 자료구조의 일종으로 double-ended queue의 약자로, 일반적인 큐와 달리 양쪽 끝에서 삽입,삭제가 모두 가능한 자료구조다.
import matplotlib.pyplot as plt
# 필수 모듈 임포트하기
강화학습 과정에 필요한 하이퍼 파라미터를 정의한다.
# 하이퍼파라미터 정의
EPISODES = 50 # 애피소드(총 플레이할 게임 수) 반복횟수
EPS_START = 0.9 # 학습 시작시 에이전트가 무작위로 행동할 확률
# ex) 0.5면 50% 절반의 확률로 무작위 행동, 나머지 절반은 학습된 방향으로 행동
# random하게 EPisolon을 두는 이유는 Agent가 가능한 모든 행동을 경험하기 위함.
EPS_END = 0.05 # 학습 막바지에 에이전트가 무작위로 행동할 확률
#EPS_START에서 END까지 점진적으로 감소시켜줌.
# --> 초반에는 경험을 많이 쌓게 하고, 점차 학습하면서 똑똑해지니깐 학습한대로 진행하게끔
EPS_DECAY = 200 # 학습 진행시 에이전트가 무작위로 행동할 확률을 감소시키는 값
GAMMA = 0.8 # 할인계수 : 에이전트가 현재 reward를 미래 reward보다 얼마나 더 가치있게 여기는지에 대한 값.
# 일종의 할인율
LR = 0.001 # 학습률
BATCH_SIZE = 64 # 배치 크기
본격적으로 Agent 모델 설계를 진행한다.

DQN 네트워크는 그림에서 보듯 Linear, Relu, Linear의 형태이며, 초반 4개의 입력(카트 위치, 카트 속도, 막대기 각도, 막대기 속도)를 입력받고, 2개의 출력으로 (왼쪽, 오른쪽)행동을 출력한다.
네트워크 자체는 매우 간단하지만, 앞서 설명한 DQN 네트워크의 특징(Memory, Act) 등의 동작 함수가 정의된다. 행동 결정과정은 엡실론 그리디(Epsilon Greedy)를 적용한 learn함수도 같이 작성한다.
Greedy : 미래를 고려하지 않고, 매 순간 가장 최선의 선택을 추구하는 것(탐욕스럽게)
Epsilon-Greedy : 단순 greedy로 할 경우, 경험이 부족하여 초반에 잘못 선택한 경로로만 이동할 수 있음.
Greedy의 단점을 해결하도록(=충분한 경험 데이터를 쌓을 수 있도록) 0~1사이의 Epsilon값을 설정, 일정 확률로 random 행동을 선택하게끔 학습/1-epsilon만큼으로는 에이전트가 추구하는 최상의 행동을 선택
Loss함수로는 MSE 오차를 제공하며, 현 상태에서 받은 reward와 agent가 받을 미래 reward의 기댓값에 Gamma를 적용하여 시간에 따른 reward 가치에 편차를 줄 수 있도록 한다.
class DQNAgent:
def __init__(self):
self.model = nn.Sequential(
nn.Linear(4, 256),#신경망은 카트 위치, 카트 속도, 막대기 각도, 막대기 속도까지 4가지 정보를 입력
nn.ReLU(),
nn.Linear(256, 2)#왼쪽으로 갈 때의 가치와 오른쪽으로 갈 때의 가치
)
self.optimizer = optim.Adam(self.model.parameters(), LR)
self.steps_done = 0 #self.steps_done은 학습을 반복할 때마다 증가
self.memory = deque(maxlen=10000)#memory에 deque사용.(큐가 가득 차면 제일 오래된것부터 삭제)
def memorize(self, state, action, reward, next_state):#에피소드 저장 함수
# self.memory = [(상태, 행동, 보상, 다음 상태)...]
self.memory.append((state,
action,
torch.FloatTensor([reward]),
torch.FloatTensor([next_state])))
def act(self, state):#행동 선택(담당)함수
eps_threshold = EPS_END + (EPS_START - EPS_END) * math.exp(-1. * self.steps_done / EPS_DECAY)
self.steps_done += 1
#무작위 숫자와 엡실론을 비교
# 엡실론 그리디(Epsilon-Greedy)
# : 초기엔 엡실론을 높게=최대한 경험을 많이 하도록 / 엡실론을 낮게 낮춰가며 = 신경망이 선택하는 비율 상승
if random.random() > eps_threshold:# 무작위 값 > 앱실론값 : 학습된 신경망이 옳다고 생각하는 쪽으로,
return self.model(state).data.max(1)[1].view(1, 1)
else:# 무작위 값 < 앱실론값 : 무작위로 행동
return torch.LongTensor([[random.randrange(2)]])
def learn(self):#메모리에 쌓아둔 경험들을 재학습(replay)하며, 학습하는 함수
if len(self.memory) < BATCH_SIZE:# 메모리에 저장된 에피소드가 batch 크기보다 작으면 그냥 학습을 거름.
return
#경험이 충분히 쌓일 때부터 학습 진행
batch = random.sample(self.memory, BATCH_SIZE) # 메모리에서 무작위로 Batch 크기만큼 가져와서 학습
states, actions, rewards, next_states = zip(*batch) #기존의 batch를 요소별 리스트로 분리해줄 수 있게끔
#리스트를 Tensor형태로
states = torch.cat(states)
actions = torch.cat(actions)
rewards = torch.cat(rewards)
next_states = torch.cat(next_states)
# 모델의 입력으로 states를 제공, 현 상태에서 했던 행동의 가치(Q값)을 current_q로 모음
current_q = self.model(states).gather(1, actions)
max_next_q = self.model(next_states).detach().max(1)[0]#에이전트가 보는 행동의 미래 가치(max_next_q)
expected_q = rewards + (GAMMA * max_next_q)# rewards(보상)+미래가치
# 행동은 expected_q를 따라가게끔, MSE_loss로 오차 계산, 역전파, 신경망 학습
loss = F.mse_loss(current_q.squeeze(), expected_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()current_q 함수를 만들기 위해 gather라는 함수를 사용하는데 자세한 과정은 아래 그림을 참고하면 해당 라인의 이해가 더 쉬울 것으로 예상된다.

Agent에게 필요한 함수는 모두 구현하였고, 이제 본격적인 학습 준비 단계를 시작한다.
Gym 라이브러리를 사용해 환경을 구성하고, Agent를 생성한다.
env = gym.make('CartPole-v0')# env : 게임 환경 / 원하는 게임을 make함수에 넣어주면 됨.
agent = DQNAgent()
score_history = [] #점수 저장용
본격적으로 학습을 위한 코드를 생성한다.
for e in range(1, EPISODES+1):#50번의 플레이(EPISODE수 만큼)
state = env.reset() # 매 시작마다 환경 초기화
steps = 0
while True: # 게임이 끝날때까지 무한루프
env.render()
state = torch.FloatTensor([state]) # 현 상태를 Tensor화
# 에이전트의 act 함수의 입력으로 state 제공
# Epsilon Greedy에 따라 행동 선택
action = agent.act(state)
# action : tensor, item 함수로 에이전트가 수행한 행동의 번호 추출
# step함수의 입력에 제공 ==> 다음 상태, reward, 종료 여부(done, Boolean Value) 출력
next_state, reward, done, _ = env.step(action.item())
# 게임이 끝났을 경우 마이너스 보상주기
if done:
reward = -1
agent.memorize(state, action, reward, next_state) # 경험(에피소드) 기억
agent.learn()
state = next_state
steps += 1
if done:
print("에피소드:{0} 점수: {1}".format(e, steps))
score_history.append(steps) #score history에 점수 저장
break
마지막으로 점수를 시각화할 수 있는 코드를 구현한다.
# 점수 시각화
plt.plot(score_history)
plt.ylabel('score')
plt.show()
다음과 같이 약 30~40번 사이의 Episode에서 충분히 학습이 진행되며 급격히 score가 올라가는 것을 확인할 수 있다.
참고
https://mangkyu.tistory.com/61
https://youtu.be/3Ch14GDY5Y8
https://bluediary8.tistory.com/18
3분딥러닝-파이토치맛 리뷰 完
'머신러닝 > Pytorch 딥러닝 기초' 카테고리의 다른 글
| LR scheduler 추천 : Cosine Annealing Warmup Restarts (0) | 2023.03.31 |
|---|---|
| [python, pytorch] dataloader 시간 지연, time delay (0) | 2021.09.13 |
| [Pytorch-기초강의] 8. 경쟁하며 학습하는 GAN (3) | 2021.06.13 |
| [Pytorch-기초강의] 7. 딥러닝을 해킹하는 적대적 공격 (0) | 2021.06.13 |
| [Pytorch-기초강의] 6. 순차적인 데이터를 처리하는 RNN(LSTM, GRU) (0) | 2021.05.25 |